How to Use General AI Agents Without Losing Control
General AI agents are most useful when they run inside bounded, inspectable workflows. This guide covers prompt contracts, long-running task structure, human checkpoints, curated environments, and reviewable artifacts for agents like Hermes, OpenClaw-style gateways, and MCPlato.
Most people do not lose control of a general AI agent because the prompt is too short. They lose control because the work was never shaped into a controllable workflow.
A general agent is not just a coding assistant. It may research, operate a browser, summarize documents, schedule work, coordinate sub-tasks, prepare artifacts, or act across a workspace. Tools such as Hermes, OpenClaw-adjacent gateways, and MCPlato point toward that broader pattern: an AI partner that can use tools and context over time. OpenClaw's public documentation is still strongly oriented around coding-agent workflows, so it is best treated here as a boundary and gateway example rather than as a full general-agent playbook.
The practical question is therefore not, “How do I write a prettier prompt?” It is: How do I design bounded, inspectable work so an agent can help without silently taking over?
Below are five practices that make general agents more reliable for knowledge work, operations, research, and multi-step execution.
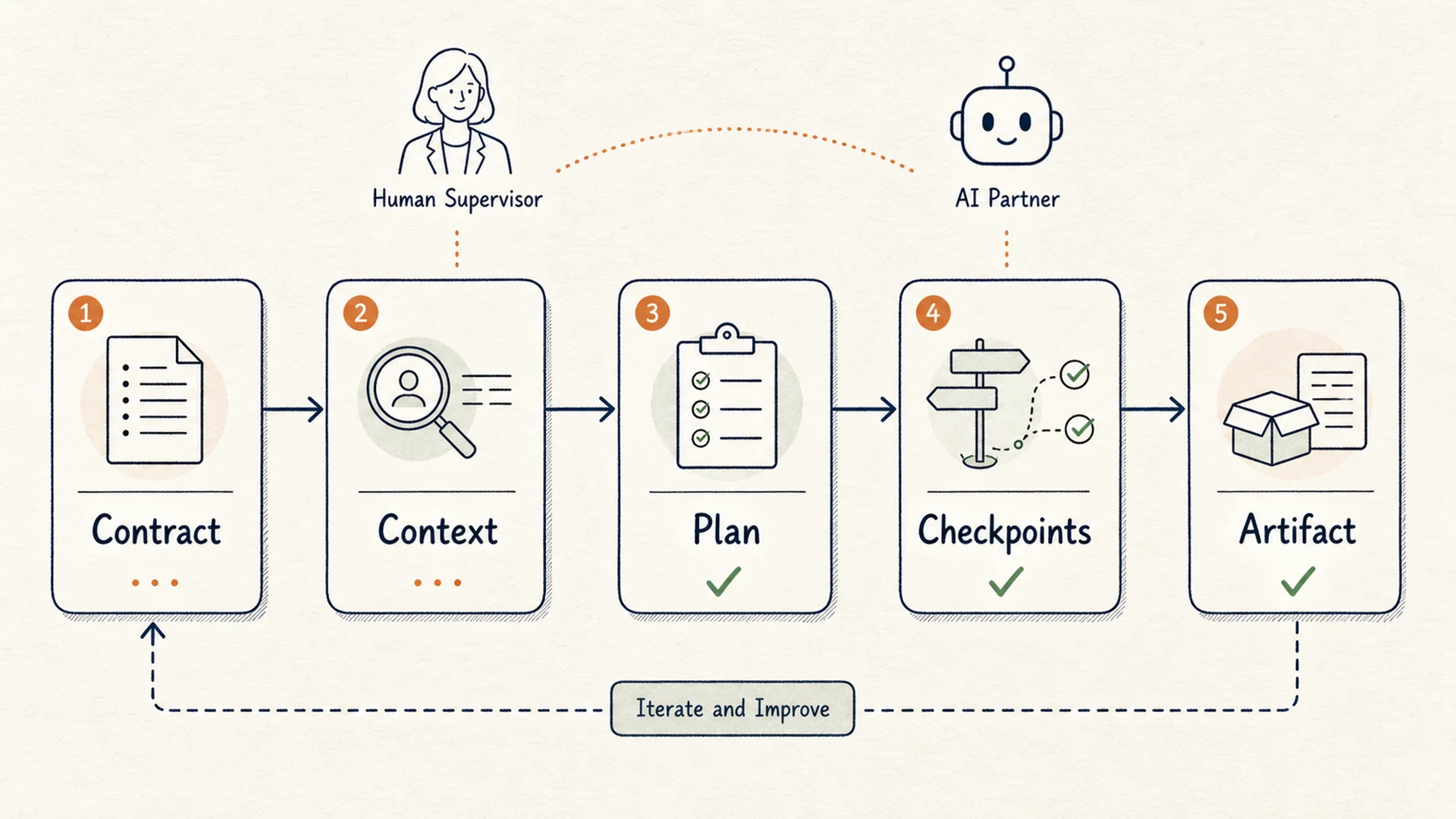 A bounded workflow diagram for using general AI agents
A bounded workflow diagram for using general AI agents
1. Write a prompt contract, not a wish
A weak instruction sounds like this:
Research this topic and make a good report.
A stronger instruction behaves like an operating contract. It tells the agent what success means, where the boundaries are, what evidence is required, and when the agent must stop.
A useful general-agent prompt should usually include:
| Contract field | What to specify |
|---|---|
| Goal | The outcome the user actually needs, not only the activity. |
| Success criteria | What must be true for the task to count as complete. |
| Failure conditions | When to stop, escalate, or report uncertainty. |
| Input materials | Which files, links, notes, datasets, or previous decisions are authoritative. |
| Tools and forbidden tools | What the agent may use, and what it must not use. |
| Confirmation actions | Which actions require approval before execution. |
| Checkpoints | Where the agent should pause and summarize progress. |
| Final artifact | The expected deliverable: memo, table, deck, ticket, plan, spreadsheet, image, or decision log. |
| Evidence | Citations, logs, screenshots, test results, file paths, or assumptions that support the result. |
This framing is consistent with prompt guidance from AWS, which emphasizes clear goals, task constraints, and expected outputs, and with Anthropic's guidance on building effective agents, where agents work best when workflows are deliberately composed rather than left as vague autonomy.
The point is not to make every prompt long. The point is to make the operational contract explicit. Short prompts are fine for short tasks. Long-running, tool-using agents need contracts.
2. Break long work into plans, checkpoints, and recovery states
General agents become fragile when they are asked to carry a long job as one uninterrupted mental thread. Long-running work should be structured as a sequence of inspectable states:
- Plan: What will be done, in what order, and why.
- Subtasks: Work units small enough to verify.
- Checkpoints: Places where the user or system can inspect progress.
- Recovery: A way to resume, retry, or roll back after interruption.
- Final synthesis: A durable artifact that summarizes what changed and what remains open.
Anthropic's orchestrator-workers pattern is useful here: a coordinating agent breaks the task into parts, while specialized workers handle bounded subtasks. LangGraph's persistence and interrupt patterns show the same architectural idea from another angle: long-running agents need state, checkpoints, and the ability to pause before sensitive actions.
Hermes also illustrates why general-agent environments need durable memory, scheduled automations, isolated subagents, and tool boundaries. These are not cosmetic features. They are what let an agent survive work that spans many steps, multiple sessions, or background execution.
In MCPlato, the same principle appears as workspace-level coordination: multiple sessions can hold different parts of the work, a virtual partner or Sprite can coordinate progress, connected materials can stay local-first, and scheduled/background tasks can continue without collapsing everything into a single chat transcript. That does not make MCPlato a magic replacement for process design. It simply makes the process design easier to preserve.
3. Put human review at risk boundaries, not every click
Human-in-the-loop control is often misunderstood. If a user must approve every tiny step, the agent becomes slower than doing the work manually. If the agent can do anything without review, the user has no real control.
The better pattern is a risk ladder.
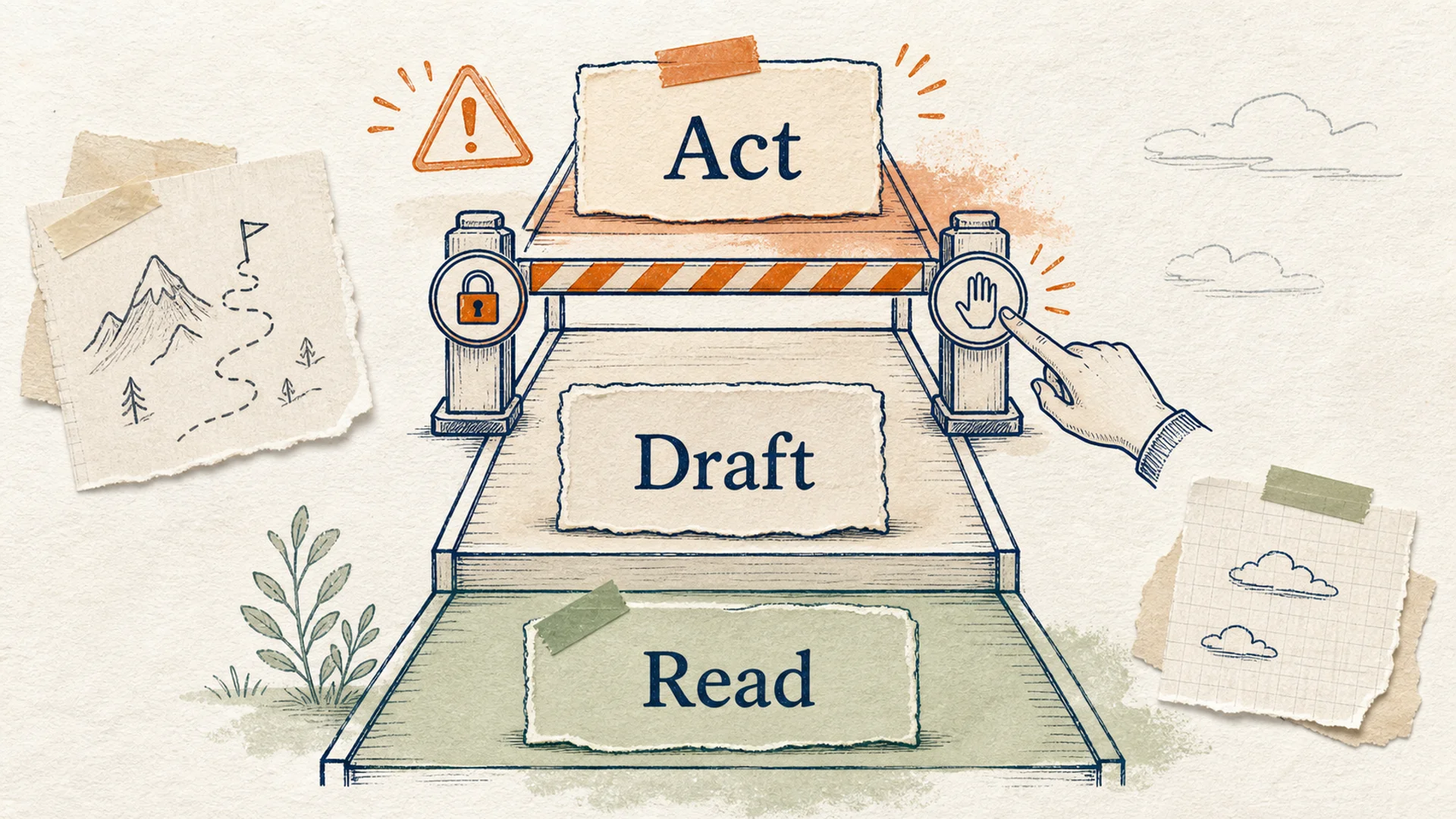 A risk ladder showing where human confirmation should happen
A risk ladder showing where human confirmation should happen
Low-risk actions can usually proceed with light supervision:
- read provided materials;
- search within an approved workspace;
- draft an outline;
- summarize sources;
- propose next steps.
Medium-risk actions should produce a checkpoint:
- modify a document;
- generate a client-facing draft;
- create a task list;
- prepare a data transformation;
- recommend a decision.
High-risk actions should require explicit confirmation:
- send a message externally;
- delete or overwrite data;
- purchase, publish, deploy, or submit;
- access sensitive systems;
- take actions that are hard to reverse.
This matches the direction of Anthropic's work on trustworthy agents and computer use, OpenAI's Agents SDK human-in-the-loop controls, and Microsoft Responsible AI guidance: supervision should be tied to risk, authority, reversibility, and impact.
A good instruction is therefore not “ask me before doing anything.” It is more specific:
You may read and summarize all provided materials. You may draft files. Before sending messages, deleting files, changing permissions, publishing, or making irreversible edits, stop and ask for confirmation with a short explanation of the risk.
That kind of boundary lets the agent remain useful while preserving human authority.
4. Curate the agent's environment before increasing autonomy
When a general agent performs poorly, users often try to fix it by adding more instruction. Sometimes the real problem is the environment.
Agents need a curated operating surface:
- Authoritative materials: Tell the agent which files, links, notes, or repositories matter most.
- Minimum necessary permissions: Give read access before write access; local access before external access; reversible actions before irreversible ones.
- Safe execution zones: Use sandboxes, drafts, staging environments, or isolated workspaces for risky work.
- Clear network boundaries: Define which sources are allowed, blocked, or preferred.
- High-signal tool output: Tools should return structured, concise, actionable results rather than noisy dumps.
- Persistent context: Important decisions, assumptions, and artifacts should outlive the chat turn.
Anthropic's computer-use and tool-writing guidance repeatedly points to the same idea: the quality of an agent depends heavily on the tools and environment around it. AWS also frames computer-use agents as systems that must manage task execution, tools, and safety constraints, not only prompts.
For general agents, this matters even more than for narrow coding agents. A coding assistant often lives inside a repository with tests, diffs, and version control. A general agent may operate across documents, calendars, browser tabs, messages, PDFs, notes, and internal policies. Without a curated environment, the agent must guess what matters.
MCPlato's local-first connected materials are one way to make this manageable: the user can attach the relevant directory, files, or project context, then let agent sessions work against that curated boundary. The important principle is portable: do not ask an agent to be autonomous in an environment you have not prepared.
5. Ask for reviewable artifacts, not just chat replies
The final output of agent work should usually be something the user can inspect without replaying the whole conversation.
For example:
| Task type | Weak output | Better artifact |
|---|---|---|
| Research | “Here is what I found.” | A sourced brief with claims, citations, and open questions. |
| Operations | “I completed the task.” | A checklist with actions taken, files changed, and unresolved items. |
| Planning | “Here is a plan.” | A milestone plan with owners, dependencies, risks, and decision points. |
| Content | “Here is a draft.” | A document with structure, references, images, and revision notes. |
| Data work | “The data is cleaned.” | A spreadsheet or table plus transformation notes and validation checks. |
Artifact-first work is becoming a common product pattern. Claude Artifacts made durable outputs more visible to users. OpenAI tracing and LangSmith observability show the adjacent operational need: when agents act, teams need traces, evidence, and inspectable state. Microsoft Responsible AI guidance similarly emphasizes accountability, monitoring, governance, and human oversight.
For a general agent, the artifact is not a decoration. It is the control surface. It lets the user ask:
- What did the agent actually produce?
- Which sources or tools supported it?
- Which decisions were made?
- Which actions are still pending?
- What should a human review before the next step?
MCPlato's artifact discipline and decision traces fit this pattern naturally: the value is not only that an AI partner can help with work, but that the work can become visible, resumable, and reviewable across sessions.
A practical starter template
If you want one reusable prompt for a general agent, start with this:
Goal:
[Describe the real outcome, not just the activity.]
Context and materials:
[Attach or list the authoritative files, links, notes, and constraints.]
Success criteria:
[Define what must be true at the end.]
Boundaries:
[Allowed tools, forbidden tools, data limits, network limits, and permission rules.]
Workflow:
1. Restate the goal and assumptions.
2. Propose a short plan.
3. Execute in small subtasks.
4. Pause at the following checkpoints: [list checkpoints].
5. Ask for confirmation before: [high-risk actions].
Evidence:
[Require citations, logs, screenshots, file paths, diffs, or validation notes.]
Final artifact:
[Specify the deliverable format and where it should be saved or displayed.]
If blocked:
[Report the blocker, what was tried, and the safest next option.]
This template is intentionally simple. It works because it turns agent use from open-ended delegation into bounded collaboration.
Conclusion: control is a workflow property
General agents will not be made reliable by prompts alone. They need clear contracts, curated context, permission boundaries, checkpoints, recovery paths, and durable artifacts.
That is true whether the agent is Hermes-style automation, an OpenClaw-adjacent gateway, MCPlato's multi-session AI partner model, or another general-agent environment. The winning pattern is not maximum autonomy. It is bounded autonomy with inspection.
When users design the workflow, agents can act with more confidence. When users skip the workflow, even a capable agent becomes a very fast source of uncertainty.
References
- AWS Prescriptive Guidance: Computer use agents
- AWS Connect: Agentic self-service prompt best practices
- Anthropic: Building effective agents
- LangGraph persistence
- LangGraph interrupts
- Hermes documentation
- Anthropic: Toward trustworthy AI agents
- Claude computer use tool documentation
- OpenAI Agents SDK: Human-in-the-loop
- Microsoft: Responsible AI for agents across the organization
- Anthropic Engineering: Writing tools for agents
- OpenClaw documentation
- Claude Artifacts
- OpenAI Agents SDK: Tracing
- LangSmith observability
- MCPlato