Why SaaS-Bench Shows AI Agents Need Harnesses, Not Just Bigger Models
SaaS-Bench tests computer-use agents on real professional SaaS workflows and exposes the gap between partial progress and verified completion. The result points to agent harnesses, workspace state, verification, permissions, and recovery as the next product layer.
Published on 2026-05-25
Less than four percent is the uncomfortable headline.
In the SaaS-Bench paper, the strongest end-to-end Resolved Score remains below four percent: Claude Opus 4.6 is reported at 43.2 overall checkpoint score and 1.9 resolved score, while GPT-5.4 High is reported at 37.0 overall checkpoint score and 3.8 resolved score in Table 2.1 The official live leaderboard, which should be treated separately from the static paper table, has also shown top systems clustered around the low-forties in checkpoint score while still landing at 3.8 or 1.9 resolved score: Claude Opus 4.7 at 43.9 checkpoint / 3.8 resolved, and GPT-5.5 High at 43.8 checkpoint / 1.9 resolved.2
That gap is the story. Computer-use agents can make visible progress through long SaaS workflows, but they rarely carry the workflow all the way to verified completion. The bottleneck is not only model intelligence. It is the missing execution system around the model: state, verification, permissions, recovery, artifacts, and workspace orchestration.
SaaS-Bench is therefore useful not because it declares that agents are weak, but because it clarifies what kind of product layer agents now need.
What SaaS-Bench Measures
SaaS-Bench is titled “SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows?” It was authored by Kean Shi, Zihang Li, Tianyi Ma, Zengji Tu, Jialong Wu, Xinbo Xu, Qingyao Yang, Ruoyu Wu, Weichu Xie, Ming Wu, Jason Zeng, Michael Heinrich, Elvis Zhang, Liang Chen, Kuan Li, and Baobao Chang.1
The benchmark evaluates agents on 23 deployable, open-source SaaS systems, across 6 professional domains and 106 tasks.1 Those domains are Software Engineering & Project Management, Business Operations & Finance, Healthcare Administration, Team Collaboration & Document Workflow, Artisan Agri-Food Supply Chain, and Independent Media Creation.1
This is important. The benchmark is not a narrow browser-clicking toy. It is closer to the kind of operational work that human professionals perform when they move between documents, project boards, dashboards, forms, calendars, finance systems, and media tools.
The task distribution makes that concrete. SaaS-Bench includes 74 text-only tasks and 32 multimodal tasks.1 It also emphasizes cross-application work: 99 of 106 tasks, or 93.4%, involve at least 2 applications, while 53 tasks, or 50.0%, involve 3 applications.1 The workflows are long as well: 72 of 74 text-only tasks, or 97.3%, exceed 100 steps, and 19 of 32 multimodal tasks, or 61.3%, exceed 100 steps.1
The official benchmark page says the suite contains 3,971 weighted verification checkpoints.2 The scoring design matters: Checkpoint Score measures weighted partial progress, while Resolved Score requires all checkpoints for a task to pass.2 In other words, the benchmark does not only ask, “Did the agent look busy?” It asks, “Did the professional workflow actually end in a verified state?”
The Checkpoint / Resolved Gap Is the Core Signal
The most revealing SaaS-Bench result is not that agents score zero. They do not. The stronger systems collect meaningful checkpoint credit. They can navigate, read, input, search, summarize, and sometimes recover enough to satisfy many intermediate conditions.
The problem is that professional workflows are multiplicative. If a task has many dependent steps, a few small defects can make the final result unusable. Missing one permission step, carrying forward stale state, updating the wrong SaaS record, failing to validate an uploaded artifact, or losing track of a cross-app dependency can leave the workflow unresolved even after visible progress.
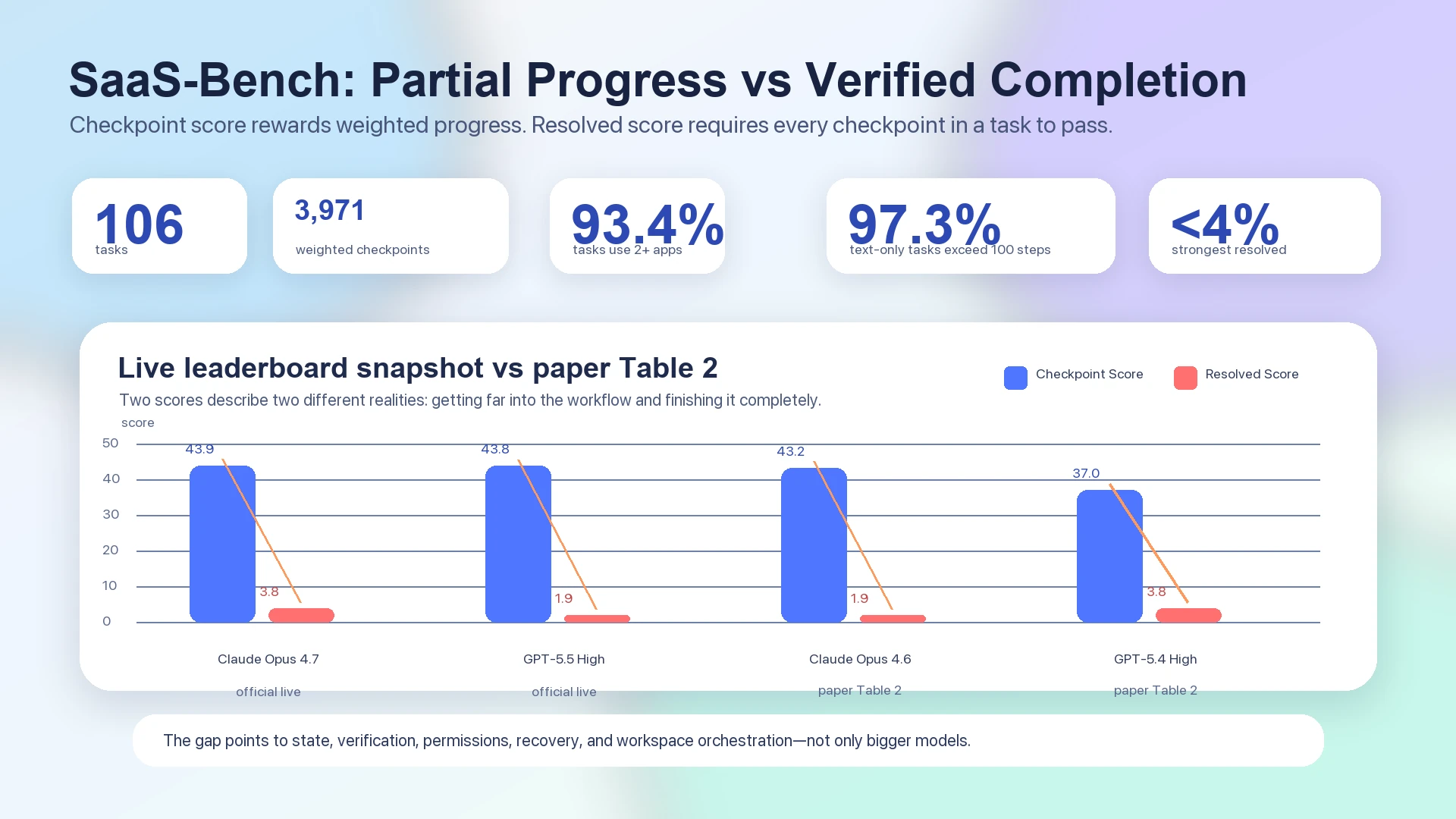 A data fracture diagram showing the SaaS-Bench gap between checkpoint progress and verified completion
A data fracture diagram showing the SaaS-Bench gap between checkpoint progress and verified completion
Figure: SaaS-Bench data separates partial progress from verified completion. The paper’s Table 2 and the official live leaderboard both show much higher checkpoint scores than resolved scores.12
This is why the benchmark is a better fit for agent architecture discussion than for simple model ranking. A pure LLM can plan, reason, and generate next actions. But a working agent must also preserve state across many steps, verify whether the world changed as expected, know when to ask for permission, retry safely, and leave behind artifacts that can be inspected.
The model is the reasoning engine. The harness is the execution system.
LLM Does Not Equal Agent
The phrase “AI agent” often collapses several layers into one word. SaaS-Bench makes that collapse harder to defend.
A language model can produce a plan such as “open the CRM, update the customer record, attach the signed document, notify the team, and reconcile the invoice.” But the professional workflow requires more than a plan. It requires the system to know which browser state is current, which SaaS app is authoritative, which file is the artifact of record, which action is reversible, which action needs user approval, and which checkpoint proves that the task is complete.
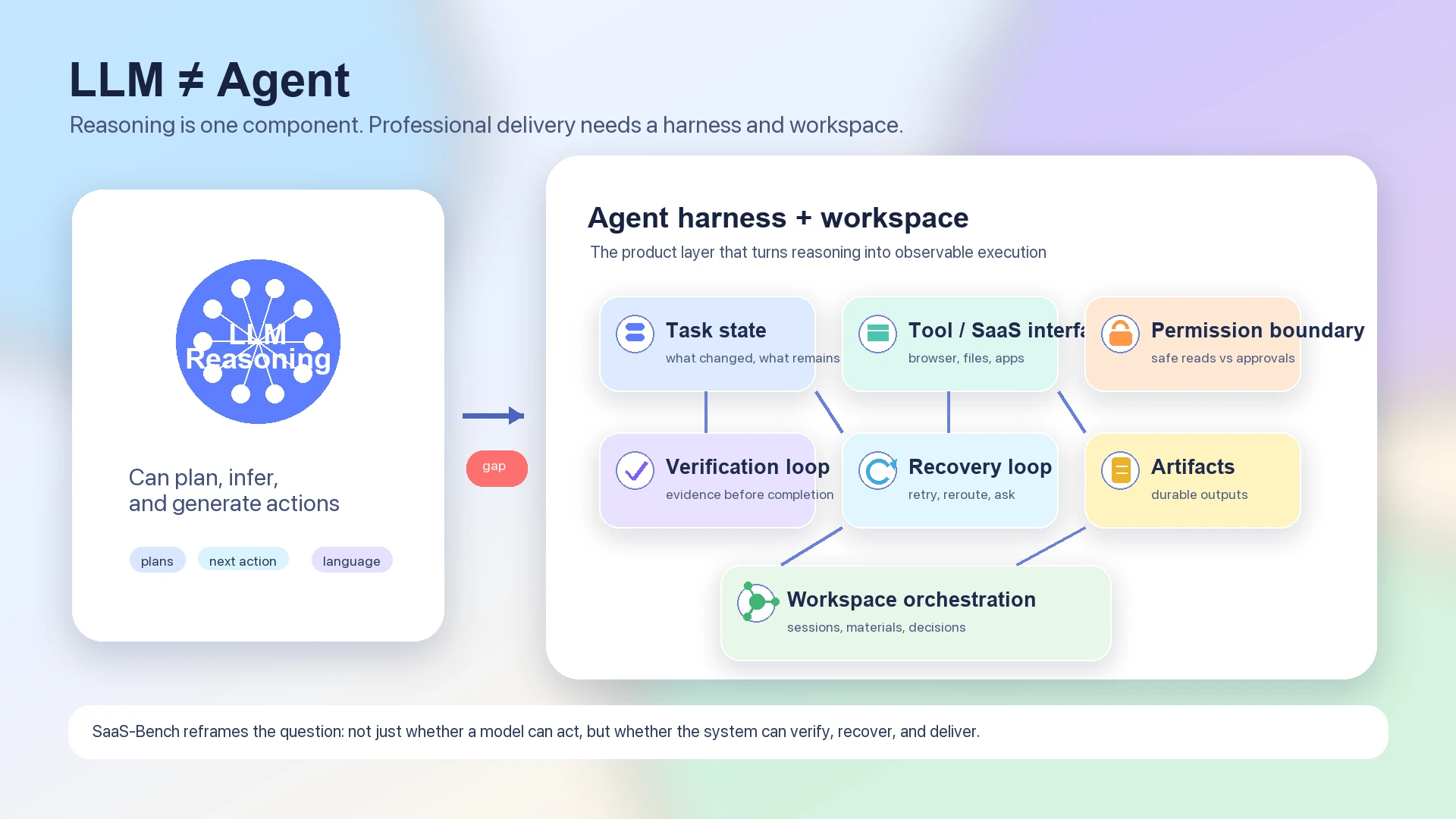 LLM is one component inside a larger agent harness and workspace architecture
LLM is one component inside a larger agent harness and workspace architecture
A useful agent stack therefore has at least these layers:
| Layer | What it contributes |
|---|---|
| LLM reasoning | Interprets goals, drafts plans, chooses next actions, and explains trade-offs. |
| Task state | Tracks what has been done, what remains open, and which assumptions are still unverified. |
| Tool and SaaS interface | Connects browser actions, documents, files, SaaS systems, and external tools into usable capabilities. |
| Permission boundary | Distinguishes safe read-only actions from actions that need explicit approval or supervision. |
| Verification loop | Checks whether each important state transition actually happened. |
| Recovery loop | Handles failures, retries, partial completion, changed UI state, and unexpected results. |
| Artifact discipline | Produces durable documents, records, tables, tickets, reports, or code changes rather than only chat replies. |
| Workspace orchestration | Coordinates multiple sessions, materials, decisions, and follow-up tasks over time. |
When these layers are weak, a stronger model can still fail. It may reason correctly in the abstract and then lose track of the concrete world. It may complete most visible steps and still miss the one verification condition that defines success. It may be capable of long reasoning but lack a safe mechanism for long-running work.
SaaS-Bench measures those missing layers indirectly. The checkpoint score shows that models can contribute. The resolved score shows that contribution is not enough.
Why Failure Is Not Just “Model Intelligence”
It is tempting to read benchmark tables as a model race. That is partly true, but it is incomplete.
For short tasks, model quality can dominate. If the work is a single answer, the strongest reasoning model often wins. For long SaaS workflows, the distribution of failures changes. The agent must act in a world that is stateful, permissioned, asynchronous, and inconsistent. The browser may not show the expected element. A document may be saved in the wrong place. A SaaS form may require a hidden validation. A notification may need to reference the correct artifact. A workflow may require going back to a previous app after a later step changes the required output.
These are harness problems as much as reasoning problems.
A stronger model may choose better actions, but it still needs an environment that can answer operational questions:
- What is the current source of truth?
- What changed after the last action?
- Which checkpoint has evidence, and which checkpoint is only assumed?
- Which step is safe to retry?
- Which operation requires user approval?
- Which artifact should be handed off as the final result?
- Which failure should trigger recovery rather than continued execution?
This is the difference between a chatbot that can describe work and an agent system that can deliver work.
A Parallel Signal from a Different SaaSBench
There is another benchmark with a similar name, and it should not be confused with SaaS-Bench. The coding-oriented SaaSBench benchmark is a different benchmark focused on complex software engineering tasks.3 Its reported setup includes 30 complex tasks, 5,370 validation nodes, 8 languages, 6 databases, and 13 frameworks, with more than 95% of failures occurring before agents reach deep business logic.3
The two benchmarks are different, but the parallel signal is useful. Whether the environment is professional SaaS operations or multi-service software engineering, many failures happen before the system reaches the deepest domain reasoning. Agents break on scaffolding: setup, state, dependencies, interfaces, validation, and recovery.
That does not make model progress irrelevant. It changes what model progress must be paired with.
The Product Layer Is Becoming the Agent Harness
The agent industry is moving from a model race to an execution-system race.
A good harness is not just a collection of tools. It is a workspace-level product layer that makes agent work inspectable and governable. It should help a user understand what the agent is doing, what it has already done, what evidence supports completion, and where human judgment is required.
For SaaS-Bench-style workflows, the harness layer needs several properties.
State continuity. Long workflows require more than context stuffing. The system needs to know the difference between a user instruction, a model hypothesis, an observed UI state, a saved artifact, and a verified decision.
Checkpoint-aware execution. If the task depends on a sequence of outcomes, the workspace should encourage explicit verification. Partial progress should be visible, but it should not be confused with completion.
Permission and action boundaries. Professional SaaS workflows often involve records, invoices, medical administration, team documents, or external communication. A mature agent system needs visible approval points and safe defaults, especially around irreversible or externally visible actions.
Recovery rather than collapse. When the UI changes or a tool fails, the system should not simply continue hallucinating progress. It should detect uncertainty, preserve the failure evidence, retry safely, or ask the user for a decision.
Artifact-first output. The end product of professional work is rarely a chat answer. It is a report, a ticket, a spreadsheet, a submitted form, a document revision, a media asset, or a decision record. A harness should treat these as durable objects.
Workspace orchestration. Many workflows are too broad for one monolithic thread. Research, execution, verification, and final reporting can be separated into sessions or workstreams, then reconciled by a workspace-level coordinator.
This is why “agent harness” and “AI workspace” are converging. The harness gives the model hands, guardrails, memory, and inspection. The workspace gives the user a place to supervise, organize, and continue the work.
Where MCPlato Fits
SaaS-Bench should not be read as a claim that any one workspace has solved autonomous SaaS work. MCPlato has not publicly claimed to run SaaS-Bench or to eliminate the benchmark’s failure modes. The responsible conclusion is narrower and more practical: the benchmark validates why workspace architecture matters.
MCPlato is designed around the idea that serious agent work needs more than a single chat transcript. At a high level, it gives users a way to organize agent execution through workspaces, sessions, connected materials, visible artifacts, and supervised continuation.
Several MCPlato concepts map naturally to the SaaS-Bench lesson:
- Multi-session orchestration. Long professional work often decomposes into research, execution, review, and synthesis. Separate sessions help preserve boundaries while still allowing the user to coordinate the overall goal.
- Sprite / virtual partner. A workspace-level partner can help track what is active, what is blocked, what is complete, and what still needs review. The value is orchestration, not theatrics.
- Artifact discipline. Outputs should become inspectable deliverables: documents, reports, plans, diagrams, code changes, or other files that can be reviewed outside the chat flow.
- Local-first connected materials. Real work depends on local documents, project folders, notes, and source materials. A workspace that keeps those materials close to the task can reduce context loss.
- Scheduled and background tasks. Some agent work benefits from continuation outside a single synchronous chat turn, especially when research, checking, or batch production is involved.
- Permissioned and observable execution. Users should be able to see what actions were attempted and decide when a step requires approval, especially when the agent touches external systems or durable artifacts.
- Decision trace. Long workflows need a memory of what was accepted, rejected, deferred, and why. Without that trace, a later agent step can accidentally undo the rationale of an earlier one.
The important wording is “helps organize and supervise.” A workspace harness does not make every agent autonomous, correct, or safe by default. It gives the user and the agent a better execution surface: one where state, artifacts, permissions, and recovery are part of the product experience rather than hidden inside a transcript.
What SaaS-Bench Suggests About the Next Agent Wave
The benchmark points toward a more realistic definition of agent progress.
The next useful agent system will not be judged only by how fluently it reasons in text. It will be judged by whether it can maintain continuity across applications, preserve evidence, recover from partial failures, ask for permission at the right time, and produce artifacts that a professional can trust.
That is a higher bar than “the model can call tools.” Tool use is only the interface. The product question is whether the surrounding harness can make tool use reliable across long workflows.
SaaS-Bench gives the industry a sharper vocabulary for that gap:
- checkpoint progress is not the same as resolved completion;
- browser control is not the same as professional workflow delivery;
- model reasoning is not the same as agent execution;
- a chat transcript is not the same as a workspace;
- autonomy without observability is not a product strategy.
The conclusion is not that bigger models do not matter. They do. But as models improve, the remaining failures become increasingly architectural. The competitive frontier moves toward harnesses, workspaces, verification loops, permission models, and artifact systems.
The model race is still happening. SaaS-Bench suggests the next race is the execution-system race.
References
Footnotes
-
SaaS-Bench arXiv paper and SaaS-Bench HTML version, including the title, authors, task composition, multi-application statistics, workflow-step statistics, scoring definitions, and Table 2 benchmark scores cited in this article. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
Official SaaS-Bench benchmark page and live leaderboard, including the official live leaderboard scores and the stated 3,971 weighted checkpoints. ↩ ↩2 ↩3 ↩4
-
SaaSBench coding benchmark arXiv paper. This is a different benchmark from SaaS-Bench; it is cited only as a background comparison signal. ↩ ↩2