SaaS-Bench가 보여주는 것: AI Agents에는 더 큰 모델만이 아니라 Harnesses가 필요하다
SaaS-Bench는 실제 전문 SaaS workflows에서 computer-use agents를 테스트하며, 부분 진행과 검증된 완료 사이의 간극을 드러낸다. 그 결과는 다음 product layer가 agent harnesses, workspace state, verification, permissions, recovery가 되어야 함을 가리킨다.
게시일 2026-05-25
4% 미만. 이것이 불편한 헤드라인이다.
SaaS-Bench paper에서 가장 강력한 end-to-end Resolved Score도 4% 아래에 머문다. Table 2는 Claude Opus 4.6을 43.2 overall checkpoint score와 1.9 resolved score로 보고하고, GPT-5.4 High를 37.0 overall checkpoint score와 3.8 resolved score로 보고한다.1 정적 paper table과 별도로 보아야 하는 공식 live leaderboard 역시 상위 시스템들이 checkpoint score에서는 40점대 초반에 모여 있지만 resolved score에서는 여전히 3.8 또는 1.9에 머무는 모습을 보여준다. Claude Opus 4.7은 43.9 checkpoint / 3.8 resolved이고, GPT-5.5 High는 43.8 checkpoint / 1.9 resolved이다.2
그 간극이 핵심이다. Computer-use agents는 긴 SaaS workflows에서 눈에 보이는 진전을 만들 수 있지만, workflow를 검증된 완료까지 끝까지 가져가는 경우는 드물다. 병목은 모델 지능만이 아니다. 모델 주변에 있어야 할 실행 시스템, 즉 state, verification, permissions, recovery, artifacts, workspace orchestration이 빠져 있는 것이다.
따라서 SaaS-Bench가 유용한 이유는 agents가 약하다고 선언하기 때문이 아니라, agents가 이제 어떤 product layer를 필요로 하는지 분명히 보여주기 때문이다.
SaaS-Bench가 측정하는 것
SaaS-Bench의 제목은 “SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows?” 이다. 저자는 Kean Shi, Zihang Li, Tianyi Ma, Zengji Tu, Jialong Wu, Xinbo Xu, Qingyao Yang, Ruoyu Wu, Weichu Xie, Ming Wu, Jason Zeng, Michael Heinrich, Elvis Zhang, Liang Chen, Kuan Li, Baobao Chang이다.1
이 benchmark는 23개의 배포 가능한 open-source SaaS systems에서 agents를 평가하며, 6개 전문 영역과 106개 task를 다룬다.1 그 영역은 Software Engineering & Project Management, Business Operations & Finance, Healthcare Administration, Team Collaboration & Document Workflow, Artisan Agri-Food Supply Chain, Independent Media Creation이다.1
이 점이 중요하다. 이 benchmark는 좁은 browser-clicking toy가 아니다. 사람들이 documents, project boards, dashboards, forms, calendars, finance systems, media tools 사이를 오가며 수행하는 실제 운영 업무에 더 가깝다.
Task distribution은 이를 구체적으로 보여준다. SaaS-Bench에는 74개의 text-only tasks와 32개의 multimodal tasks가 포함된다.1 또한 cross-application work를 강조한다. 106개 task 중 99개, 즉 **93.4%**가 최소 2개의 applications를 포함하고, 53개 task, 즉 **50.0%**가 3개의 applications를 포함한다.1 Workflows도 길다. 74개의 text-only tasks 중 72개, 즉 **97.3%**가 100 steps를 넘고, 32개의 multimodal tasks 중 19개, 즉 **61.3%**가 100 steps를 넘는다.1
공식 benchmark 페이지는 이 suite에 3,971개의 weighted verification checkpoints가 포함된다고 말한다.2 Scoring design이 중요하다. Checkpoint Score는 가중치가 적용된 부분 진행을 측정하고, Resolved Score는 task의 모든 checkpoints가 통과할 것을 요구한다.2 다시 말해 benchmark는 “agent가 바빠 보였는가?”만 묻지 않는다. “전문 workflow가 실제로 검증된 상태로 끝났는가?”를 묻는다.
Checkpoint / Resolved 간극이 핵심 신호다
가장 드러나는 SaaS-Bench 결과는 agents가 0점을 받는다는 것이 아니다. 그렇지 않다. 더 강한 시스템들은 의미 있는 checkpoint credit을 얻는다. 탐색하고, 읽고, 입력하고, 검색하고, 요약하며, 때로는 많은 중간 조건을 만족할 만큼 복구할 수도 있다.
문제는 전문 workflows가 곱셈적이라는 점이다. Task에 의존적인 steps가 많으면, 작은 결함 몇 개만으로도 최종 결과가 쓸모없어질 수 있다. permission step 하나를 놓치거나, stale state를 계속 가져가거나, 잘못된 SaaS record를 업데이트하거나, 업로드된 artifact를 검증하지 못하거나, cross-app dependency를 놓치면, 눈에 보이는 진전이 있어도 workflow는 unresolved로 남을 수 있다.
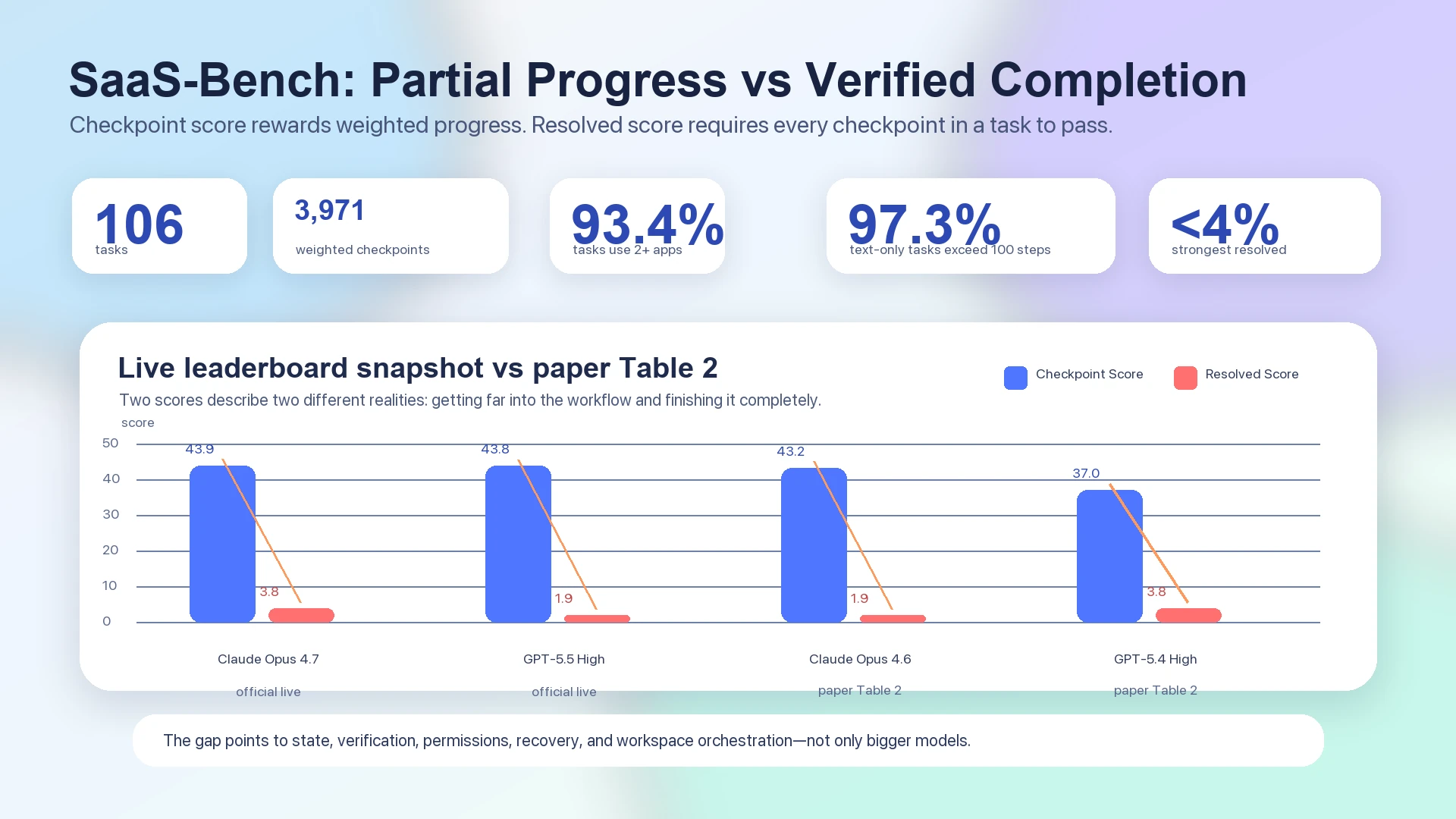 SaaS-Bench에서 checkpoint progress와 verified completion 사이의 간극을 보여주는 데이터 균열 다이어그램
SaaS-Bench에서 checkpoint progress와 verified completion 사이의 간극을 보여주는 데이터 균열 다이어그램
그림: SaaS-Bench data는 부분 진행과 검증된 완료를 분리한다. Paper의 Table 2와 공식 live leaderboard 모두 checkpoint scores가 resolved scores보다 훨씬 높다는 것을 보여준다.12
그래서 이 benchmark는 단순한 모델 순위보다 agent architecture 논의에 더 잘 맞는다. 순수 LLM은 계획하고, 추론하고, next actions를 생성할 수 있다. 하지만 작동하는 agent는 여러 steps에 걸쳐 state를 보존하고, 세계가 예상대로 바뀌었는지 검증하고, 언제 permission을 요청해야 하는지 알고, 안전하게 retry하며, 검사 가능한 artifacts를 남겨야 한다.
모델은 reasoning engine이다. Harness는 execution system이다.
LLM은 Agent와 같지 않다
“AI agent”라는 표현은 여러 layer를 하나의 단어로 접어 넣는 경우가 많다. SaaS-Bench는 그런 압축을 더 방어하기 어렵게 만든다.
언어 모델은 “CRM을 열고, customer record를 업데이트하고, signed document를 첨부하고, 팀에 알리고, invoice를 조정하라” 같은 계획을 만들 수 있다. 하지만 전문 workflow에는 계획 이상의 것이 필요하다. 시스템은 어떤 browser state가 현재인지, 어떤 SaaS app이 authoritative인지, 어떤 file이 artifact of record인지, 어떤 action이 reversible인지, 어떤 action이 user approval을 필요로 하는지, 어떤 checkpoint가 task 완료를 증명하는지 알아야 한다.
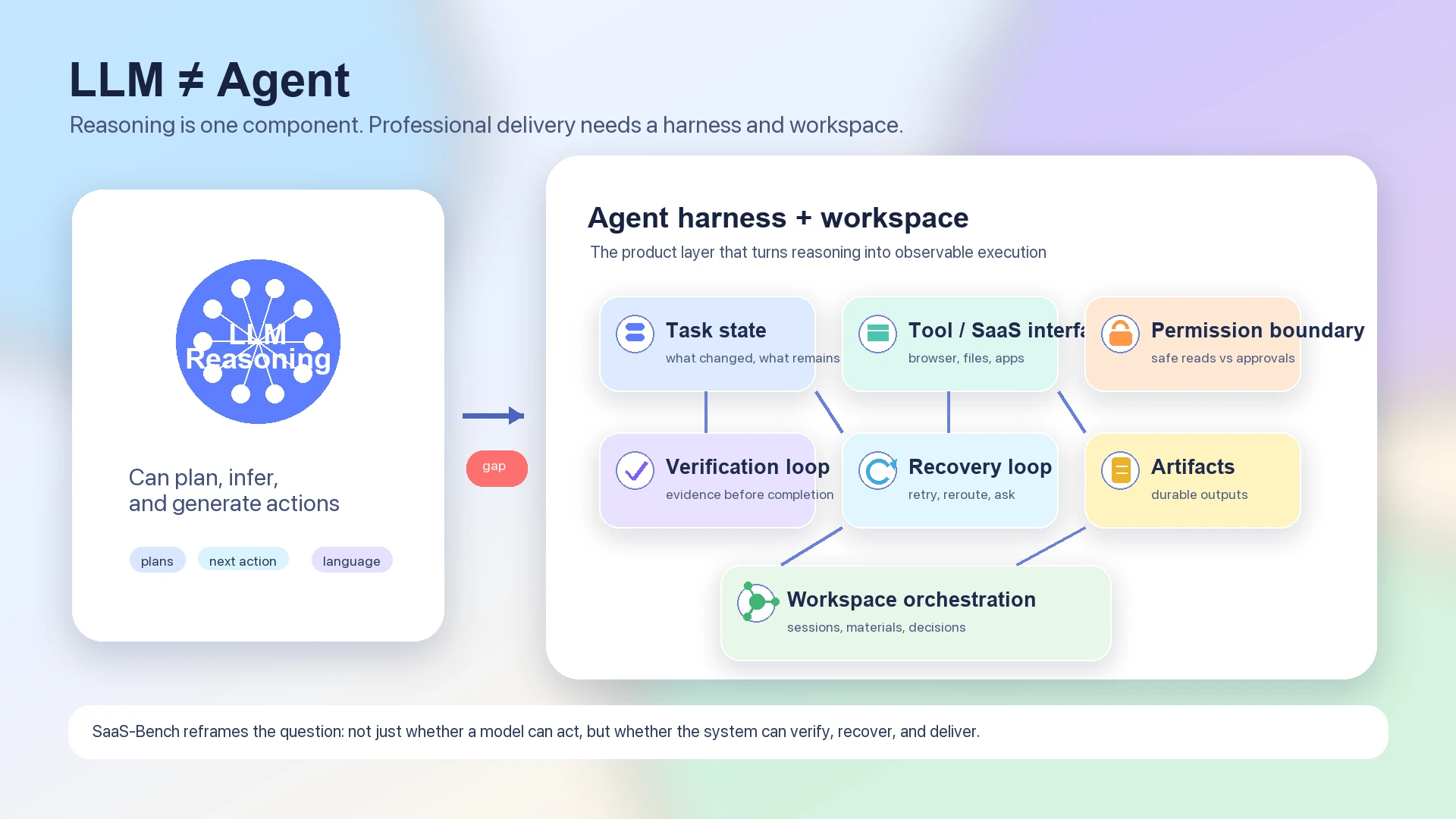 LLM이 더 큰 agent harness와 workspace architecture 안의 한 구성 요소임을 보여주는 다이어그램
LLM이 더 큰 agent harness와 workspace architecture 안의 한 구성 요소임을 보여주는 다이어그램
따라서 유용한 agent stack에는 최소한 다음 layer들이 필요하다.
| Layer | 기여 |
|---|---|
| LLM reasoning | 목표를 해석하고, 계획을 작성하고, next actions를 선택하며, trade-offs를 설명한다. |
| Task state | 무엇이 완료되었고, 무엇이 남아 있으며, 어떤 가정이 아직 검증되지 않았는지 추적한다. |
| Tool and SaaS interface | Browser actions, documents, files, SaaS systems, external tools를 usable capabilities로 연결한다. |
| Permission boundary | 안전한 read-only actions와 명시적 approval 또는 supervision이 필요한 actions를 구분한다. |
| Verification loop | 중요한 state transition이 실제로 일어났는지 확인한다. |
| Recovery loop | Failures, retries, partial completion, 변경된 UI state, 예상치 못한 결과를 처리한다. |
| Artifact discipline | chat replies만이 아니라 durable documents, records, tables, tickets, reports, code changes를 만든다. |
| Workspace orchestration | 여러 sessions, materials, decisions, follow-up tasks를 시간에 걸쳐 조율한다. |
이 layer들이 약하면 더 강한 모델도 실패할 수 있다. 추상적으로는 올바르게 reasoning하고도 구체적인 세계를 놓칠 수 있다. 대부분의 visible steps를 완료하고도 성공을 정의하는 하나의 verification condition을 놓칠 수 있다. Long reasoning은 가능하지만 long-running work를 위한 안전한 mechanism은 없을 수 있다.
SaaS-Bench는 이런 누락된 layer들을 간접적으로 측정한다. Checkpoint score는 모델이 기여할 수 있음을 보여준다. Resolved score는 그 기여만으로는 충분하지 않음을 보여준다.
실패는 단지 “모델 지능” 문제가 아니다
Benchmark table을 모델 경쟁으로 읽고 싶은 유혹이 있다. 부분적으로는 맞지만, 그것만으로는 부족하다.
짧은 task에서는 모델 품질이 지배적일 수 있다. 일이 하나의 답변이라면 가장 강한 reasoning model이 자주 이긴다. 긴 SaaS workflows에서는 실패의 분포가 바뀐다. Agent는 stateful, permissioned, asynchronous, inconsistent한 세계에서 행동해야 한다. 브라우저가 예상한 element를 보여주지 않을 수 있다. Document가 잘못된 위치에 저장될 수 있다. SaaS form이 숨겨진 validation을 요구할 수 있다. Notification이 올바른 artifact를 참조해야 할 수 있다. Workflow가 나중 step에서 필요한 output이 바뀐 뒤 이전 app으로 돌아가야 할 수도 있다.
이것들은 reasoning problems인 동시에 harness problems이다.
더 강한 모델은 더 나은 actions를 선택할 수 있지만, 여전히 운영적 질문에 답할 수 있는 환경이 필요하다.
- 현재 source of truth는 무엇인가?
- 마지막 action 이후 무엇이 바뀌었는가?
- 어떤 checkpoint에는 evidence가 있고, 어떤 checkpoint는 assumed일 뿐인가?
- 어떤 step은 안전하게 retry할 수 있는가?
- 어떤 operation에는 user approval이 필요한가?
- 어떤 artifact를 최종 결과로 hand off해야 하는가?
- 어떤 failure가 continued execution이 아니라 recovery를 trigger해야 하는가?
이것이 일을 설명할 수 있는 chatbot과 일을 deliver할 수 있는 agent system의 차이다.
다른 SaaSBench에서 온 병렬 신호
비슷한 이름의 또 다른 benchmark가 있으며, SaaS-Bench와 혼동해서는 안 된다. Coding-oriented SaaSBench benchmark는 복잡한 software engineering tasks에 초점을 맞춘 다른 benchmark다.3 보고된 setup에는 30개의 complex tasks, 5,370개의 validation nodes, 8개의 languages, 6개의 databases, 13개의 frameworks가 포함되며, failures의 95% 이상이 agents가 deep business logic에 도달하기 전에 발생한다.3
두 benchmark는 다르지만 병렬 신호는 유용하다. 환경이 professional SaaS operations이든 multi-service software engineering이든, 많은 failures는 시스템이 가장 깊은 domain reasoning에 도달하기 전에 발생한다. Agents는 scaffolding에서 무너진다. setup, state, dependencies, interfaces, validation, recovery에서다.
그렇다고 모델 발전이 무의미한 것은 아니다. 모델 발전이 무엇과 함께 가야 하는지가 달라진다.
Product Layer는 Agent Harness가 되고 있다
Agent industry는 모델 경쟁에서 execution-system 경쟁으로 이동하고 있다.
좋은 harness는 단순한 tools 모음이 아니다. Agent work를 inspectable하고 governable하게 만드는 workspace-level product layer다. 사용자가 agent가 무엇을 하고 있는지, 이미 무엇을 했는지, completion을 뒷받침하는 evidence가 무엇인지, 어디에서 human judgment가 필요한지 이해하도록 도와야 한다.
SaaS-Bench 스타일 workflows에서 harness layer에는 여러 속성이 필요하다.
State continuity. 긴 workflows에는 context stuffing 이상이 필요하다. 시스템은 user instruction, model hypothesis, observed UI state, saved artifact, verified decision의 차이를 알아야 한다.
Checkpoint-aware execution. Task가 outcomes의 sequence에 의존한다면 workspace는 명시적 verification을 장려해야 한다. 부분 진행은 보여야 하지만 completion과 혼동되어서는 안 된다.
Permission and action boundaries. 전문 SaaS workflows는 records, invoices, medical administration, team documents, external communication을 자주 포함한다. 성숙한 agent system에는 특히 irreversible하거나 externally visible한 actions 주변에서 visible approval points와 safe defaults가 필요하다.
Recovery rather than collapse. UI가 바뀌거나 tool이 실패할 때 시스템은 progress를 hallucinate하며 계속해서는 안 된다. uncertainty를 감지하고, failure evidence를 보존하고, 안전하게 retry하거나, 사용자에게 decision을 요청해야 한다.
Artifact-first output. 전문 업무의 최종 산출물은 chat answer인 경우가 드물다. Report, ticket, spreadsheet, submitted form, document revision, media asset, decision record일 수 있다. Harness는 이를 durable objects로 다루어야 한다.
Workspace orchestration. 많은 workflows는 하나의 monolithic thread에 담기에는 너무 넓다. Research, execution, verification, final reporting은 sessions 또는 workstreams로 분리한 뒤 workspace-level coordinator가 reconcile할 수 있다.
이것이 “agent harness”와 “AI workspace”가 수렴하는 이유다. Harness는 모델에 hands, guardrails, memory, inspection을 제공한다. Workspace는 사용자가 work를 supervise, organize, continue할 장소를 제공한다.
MCPlato가 들어맞는 위치
SaaS-Bench를 어떤 하나의 workspace가 autonomous SaaS work를 해결했다는 주장으로 읽어서는 안 된다. MCPlato는 SaaS-Bench를 실행했다고 공개적으로 주장한 적도, benchmark의 failure modes를 제거했다고 주장한 적도 없다. 책임 있는 결론은 더 좁고 실용적이다. 이 benchmark는 workspace architecture가 왜 중요한지를 검증한다.
MCPlato는 진지한 agent work에는 하나의 chat transcript 이상이 필요하다는 생각을 중심으로 설계되었다. 높은 수준에서 MCPlato는 users가 workspaces, sessions, connected materials, visible artifacts, supervised continuation을 통해 agent execution을 조직할 수 있게 해준다.
여러 MCPlato 개념은 SaaS-Bench의 교훈과 자연스럽게 대응한다.
- Multi-session orchestration. 긴 전문 업무는 research, execution, review, synthesis로 분해되는 경우가 많다. 분리된 sessions는 boundaries를 보존하면서도 사용자가 전체 목표를 조율하게 해준다.
- Sprite / virtual partner. Workspace-level partner는 무엇이 active인지, 무엇이 blocked인지, 무엇이 complete인지, 무엇이 아직 review가 필요한지 추적하도록 도울 수 있다. 가치는 theatrics가 아니라 orchestration에 있다.
- Artifact discipline. Outputs는 검사 가능한 deliverables가 되어야 한다. Documents, reports, plans, diagrams, code changes, 또는 chat flow 밖에서 review할 수 있는 다른 files다.
- Local-first connected materials. 실제 work는 local documents, project folders, notes, source materials에 의존한다. 그런 materials를 task 가까이에 두는 workspace는 context loss를 줄일 수 있다.
- Scheduled and background tasks. 일부 agent work는 하나의 synchronous chat turn 밖에서 continuation될 때 유리하다. 특히 research, checking, batch production이 관련될 때 그렇다.
- Permissioned and observable execution. Users는 어떤 actions가 시도되었는지 볼 수 있어야 하고, agent가 external systems 또는 durable artifacts를 다룰 때 어떤 step에 approval이 필요한지 결정할 수 있어야 한다.
- Decision trace. 긴 workflows에는 무엇이 accepted, rejected, deferred되었고 왜 그랬는지에 대한 memory가 필요하다. 그 trace가 없으면 이후 agent step이 이전 rationale을 우발적으로 되돌릴 수 있다.
중요한 표현은 “조직하고 감독하도록 돕는다”이다. Workspace harness가 모든 agent를 기본적으로 autonomous, correct, safe하게 만드는 것은 아니다. 그것은 사용자와 agent에게 더 나은 execution surface를 제공한다. State, artifacts, permissions, recovery가 transcript 안에 숨는 것이 아니라 product experience의 일부가 되는 표면이다.
SaaS-Bench가 다음 Agent 물결에 대해 시사하는 것
이 benchmark는 agent progress에 대한 더 현실적인 정의를 가리킨다.
다음의 유용한 agent system은 텍스트에서 얼마나 유창하게 reasoning하는지만으로 평가되지 않을 것이다. Applications 전반에서 continuity를 유지하고, evidence를 보존하고, partial failures에서 recover하고, 적절한 때 permission을 요청하고, 전문가가 신뢰할 수 있는 artifacts를 만들어낼 수 있는지로 평가될 것이다.
이는 “모델이 tools를 호출할 수 있다”보다 높은 기준이다. Tool use는 interface일 뿐이다. Product question은 주변 harness가 긴 workflows 전반에서 tool use를 reliable하게 만들 수 있는지다.
SaaS-Bench는 그 간극을 설명할 더 날카로운 어휘를 industry에 제공한다.
- checkpoint progress는 resolved completion과 같지 않다;
- browser control은 professional workflow delivery와 같지 않다;
- model reasoning은 agent execution과 같지 않다;
- chat transcript는 workspace와 같지 않다;
- observability 없는 autonomy는 product strategy가 아니다.
결론은 더 큰 모델이 중요하지 않다는 것이 아니다. 중요하다. 하지만 모델이 개선될수록 남은 failures는 점점 더 architectural해진다. 경쟁의 최전선은 harnesses, workspaces, verification loops, permission models, artifact systems로 이동한다.
모델 경쟁은 여전히 진행 중이다. SaaS-Bench는 다음 경쟁이 execution-system race임을 시사한다.
References
Footnotes
-
SaaS-Bench arXiv paper 및 SaaS-Bench HTML version. 이 글에서 인용한 title, authors, task composition, multi-application statistics, workflow-step statistics, scoring definitions, Table 2 benchmark scores를 포함한다. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
Official SaaS-Bench benchmark page and live leaderboard. 공식 live leaderboard scores와 명시된 3,971 weighted checkpoints를 포함한다. ↩ ↩2 ↩3 ↩4
-
SaaSBench coding benchmark arXiv paper. 이는 SaaS-Bench와 다른 benchmark이며, 배경 비교 신호로만 인용했다. ↩ ↩2