SaaS-Bench が示すもの:AI Agent に必要なのは、より大きなモデルだけでなく Harness である
SaaS-Bench は、実際の専門的な SaaS ワークフローで computer-use agents をテストし、部分的な進捗と検証済み完了のギャップを明らかにする。その結果は、agent harness、workspace state、verification、permissions、recovery が次のプロダクトレイヤーになることを示している。
公開日 2026-05-25
4% 未満。これが、受け入れがたい見出しである。
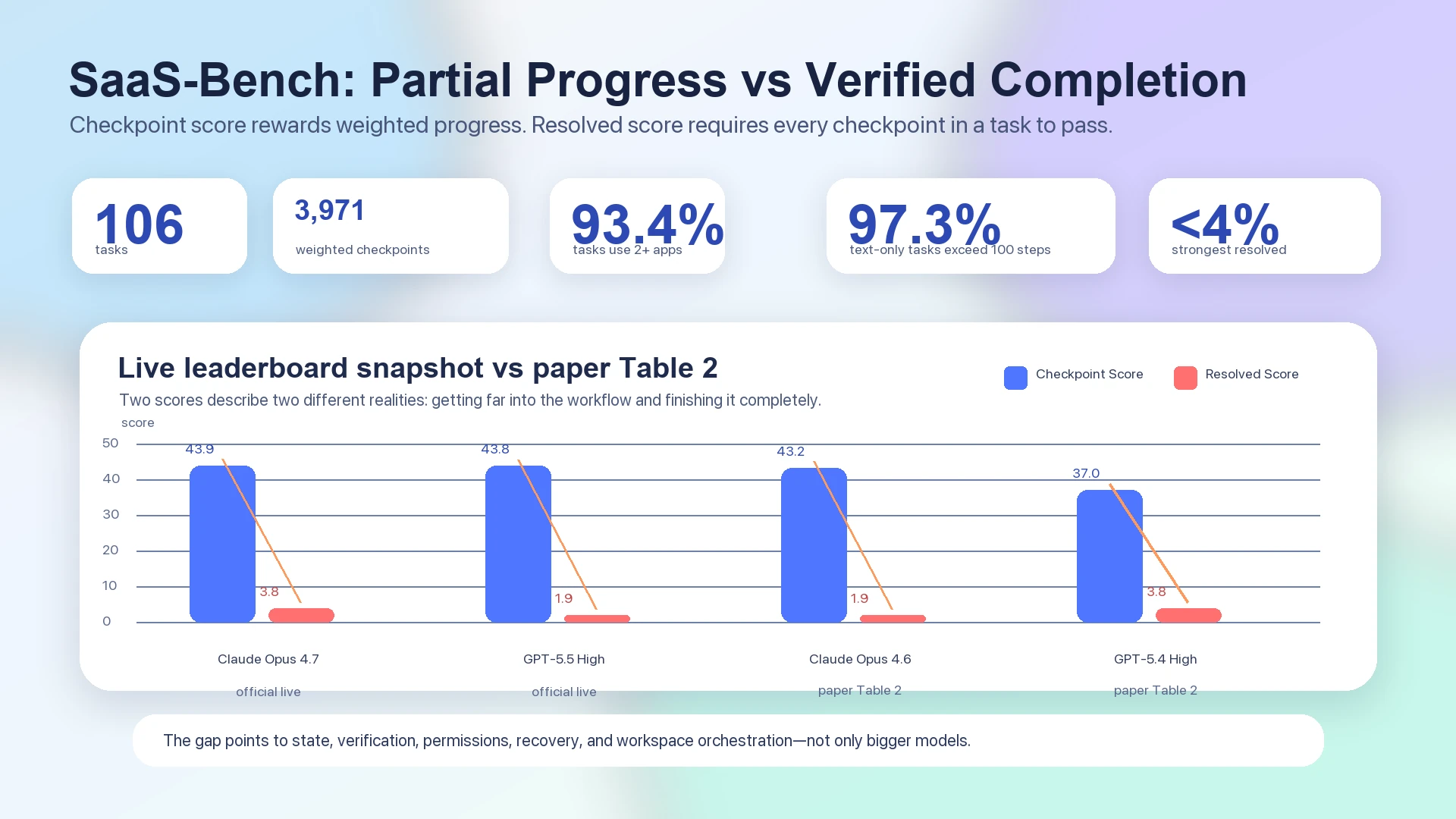
SaaS-Bench の論文では、最も強いエンドツーエンドの Resolved Score でさえ 4% を下回っている。Table 2 では、Claude Opus 4.6 が 43.2 の overall checkpoint score と 1.9 の resolved score、GPT-5.4 High が 37.0 の overall checkpoint score と 3.8 の resolved score と報告されている。1 静的な論文の表とは別に扱うべき公式ライブリーダーボードでも、上位システムの checkpoint score は 40 台前半に集まる一方、resolved score は 3.8 または 1.9 にとどまっている。Claude Opus 4.7 は 43.9 checkpoint / 3.8 resolved、GPT-5.5 High は 43.8 checkpoint / 1.9 resolved である。2
このギャップこそが本質だ。Computer-use agents は長い SaaS ワークフローの中で目に見える進捗を作れる。しかし、ワークフローを検証済みの完了まで運び切ることはほとんどない。ボトルネックはモデルの知能だけではない。モデルの周囲にあるべき実行システム、つまり state、verification、permissions、recovery、artifacts、workspace orchestration が欠けていることにある。
したがって SaaS-Bench が有用なのは、agents が弱いと宣言するからではない。今 agents に必要なプロダクトレイヤーの種類を明確にするからである。
SaaS-Bench が測定するもの
SaaS-Bench のタイトルは “SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows?” である。著者は Kean Shi、Zihang Li、Tianyi Ma、Zengji Tu、Jialong Wu、Xinbo Xu、Qingyao Yang、Ruoyu Wu、Weichu Xie、Ming Wu、Jason Zeng、Michael Heinrich、Elvis Zhang、Liang Chen、Kuan Li、Baobao Chang である。1
この benchmark は、23 個のデプロイ可能な open-source SaaS システム上で agents を評価し、6 つの専門領域と 106 個のタスクを対象にしている。1 それらの領域は Software Engineering & Project Management、Business Operations & Finance、Healthcare Administration、Team Collaboration & Document Workflow、Artisan Agri-Food Supply Chain、Independent Media Creation である。1
これは重要だ。この benchmark は、狭いブラウザクリックのおもちゃではない。人間の専門職が文書、プロジェクトボード、ダッシュボード、フォーム、カレンダー、財務システム、メディアツールの間を移動しながら行う運用業務に近い。
タスク分布はそれを具体的に示している。SaaS-Bench には 74 個の text-only tasks と 32 個の multimodal tasks が含まれる。1 また、cross-application work も重視されている。106 個中 99 個、つまり 93.4% のタスクが少なくとも 2 つのアプリケーションを含み、53 個、つまり 50.0% のタスクが 3 つのアプリケーションを含む。1 ワークフローも長い。74 個の text-only tasks のうち 72 個、つまり 97.3% が 100 ステップを超え、32 個の multimodal tasks のうち 19 個、つまり 61.3% が 100 ステップを超える。1
公式 benchmark ページによれば、このスイートには 3,971 個の weighted verification checkpoints が含まれる。2 スコア設計は重要である。Checkpoint Score は重み付きの部分進捗を測定し、Resolved Score はタスク内のすべての checkpoints が合格することを要求する。2 つまり、この benchmark は「agent は忙しそうに見えたか」だけを問うのではない。「専門的なワークフローは、実際に検証済みの状態で終わったか」を問うのである。
Checkpoint / Resolved のギャップが中核的なシグナルである
SaaS-Bench の結果で最も示唆的なのは、agents がゼロ点を取っていることではない。実際にはそうではない。強いシステムは意味のある checkpoint credit を集める。ナビゲートし、読み、入力し、検索し、要約し、ときには多くの中間条件を満たす程度まで復旧できる。
問題は、専門的なワークフローが乗法的であることだ。タスクに多くの依存ステップがある場合、少数の小さな欠陥で最終結果が使えなくなる。permission step を 1 つ見落とす、古い state を引き継ぐ、誤った SaaS record を更新する、アップロードされた artifact を検証しない、cross-app dependency を見失う。こうしたことが起きると、目に見える進捗があってもワークフローは unresolved のままになり得る。
 SaaS-Bench における checkpoint progress と verified completion のギャップを示すデータ断裂図
SaaS-Bench における checkpoint progress と verified completion のギャップを示すデータ断裂図
図: SaaS-Bench のデータは、部分的な進捗と検証済み完了を分離している。論文の Table 2 と公式ライブリーダーボードはいずれも、checkpoint scores が resolved scores より大幅に高いことを示している。12
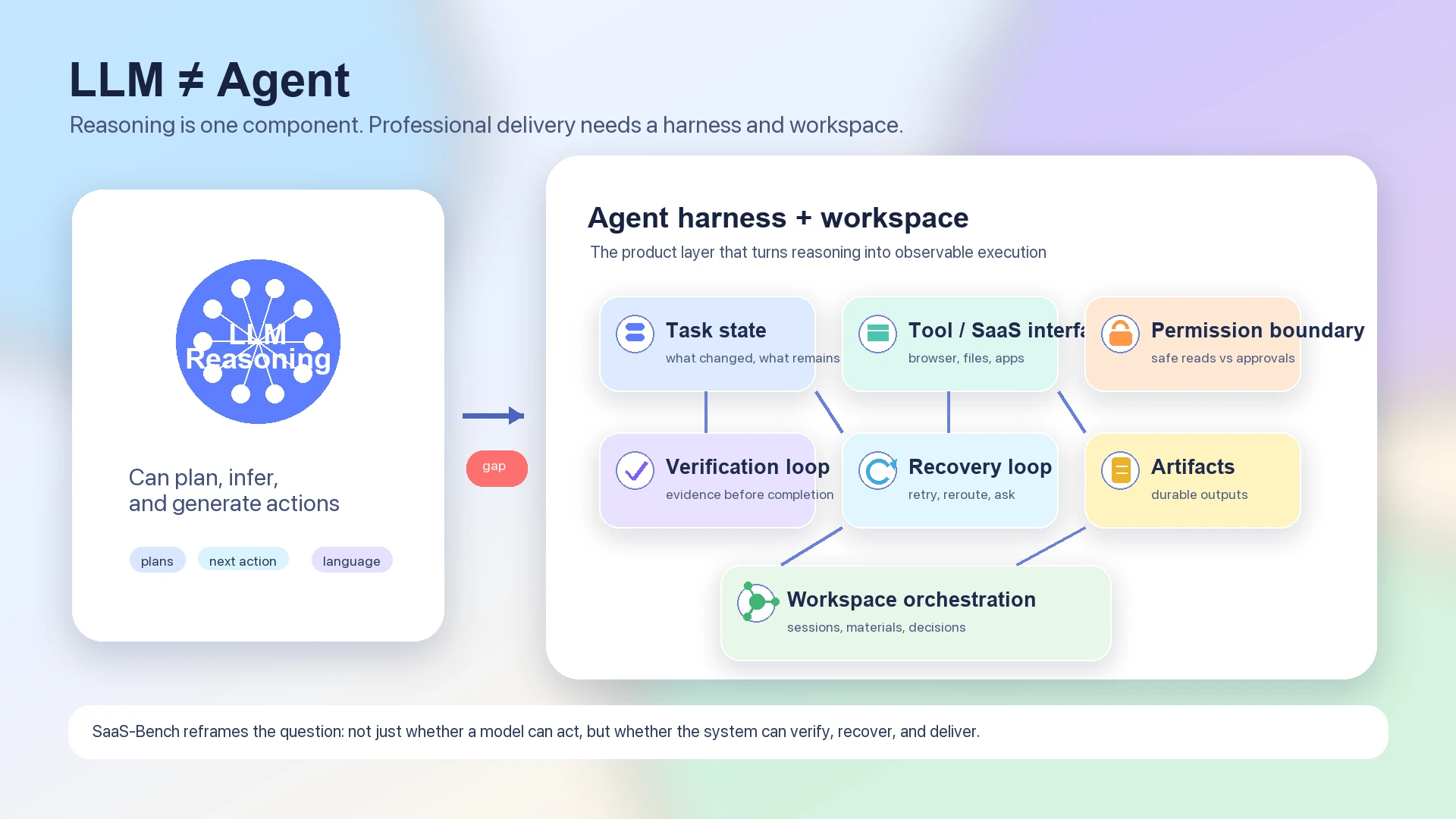
だからこそ、この benchmark は単純なモデルランキングよりも agent architecture の議論に適している。純粋な LLM は計画し、推論し、次のアクションを生成できる。しかし実際に機能する agent は、多数のステップにまたがって state を保持し、世界が期待どおりに変化したかを検証し、いつ permission を求めるべきかを理解し、安全に再試行し、検査可能な artifacts を残さなければならない。
モデルは推論エンジンである。Harness は実行システムである。
LLM は Agent と同じではない
“AI agent” という言葉は、しばしば複数のレイヤーを 1 つの単語に押し込めてしまう。SaaS-Bench は、その圧縮を正当化しにくくする。
言語モデルは「CRM を開き、顧客レコードを更新し、署名済み文書を添付し、チームに通知し、請求書を照合する」といった計画を作れる。しかし専門的なワークフローに必要なのは計画だけではない。システムは、どの browser state が現在のものか、どの SaaS app が authoritative か、どのファイルが artifact of record か、どの action が reversible か、どの action が user approval を必要とするか、どの checkpoint がタスク完了を証明するかを知る必要がある。
 LLM がより大きな agent harness と workspace architecture の一構成要素であることを示す図
LLM がより大きな agent harness と workspace architecture の一構成要素であることを示す図
したがって、有用な agent stack には少なくとも次のレイヤーが必要である。
| レイヤー | 役割 |
|---|---|
| LLM reasoning | 目標を解釈し、計画を起草し、次の action を選び、trade-off を説明する。 |
| Task state | 何が完了し、何が未解決で、どの仮定がまだ未検証かを追跡する。 |
| Tool and SaaS interface | ブラウザ操作、文書、ファイル、SaaS systems、外部ツールを利用可能な capabilities として接続する。 |
| Permission boundary | 安全な read-only actions と、明示的な approval または supervision が必要な actions を区別する。 |
| Verification loop | 重要な state transition が実際に起きたかを確認する。 |
| Recovery loop | 失敗、再試行、部分完了、UI state の変化、予期しない結果を扱う。 |
| Artifact discipline | chat replies だけでなく、耐久的な documents、records、tables、tickets、reports、code changes を生成する。 |
| Workspace orchestration | 時間をかけて複数の sessions、materials、decisions、follow-up tasks を調整する。 |
これらのレイヤーが弱いと、より強いモデルでも失敗する可能性がある。抽象的には正しく推論しても、具体的な世界を見失うことがある。見えるステップの大半を完了しても、成功を定義する 1 つの verification condition を逃すことがある。長い推論ができても、長時間実行される作業のための安全な mechanism を欠くことがある。
SaaS-Bench は、こうした欠けているレイヤーを間接的に測定している。Checkpoint score はモデルが貢献できることを示す。Resolved score は、その貢献だけでは不十分であることを示す。
失敗は単なる「モデル知能」ではない
benchmark の表をモデル競争として読むのは魅力的だ。それは部分的には正しいが、不完全である。
短いタスクでは、モデル品質が支配的になり得る。作業が 1 回の回答で済むなら、最も強い reasoning model が勝つことが多い。長い SaaS ワークフローでは、失敗の分布が変わる。Agent は stateful、permissioned、asynchronous、inconsistent な世界で行動しなければならない。ブラウザに期待した要素が表示されないことがある。文書が間違った場所に保存されることがある。SaaS フォームが隠れた validation を要求することがある。通知は正しい artifact を参照する必要がある。後のステップで必要な出力が変わり、以前の app に戻る必要が生じることもある。
これらは reasoning problems であると同時に harness problems でもある。
より強いモデルはより良い actions を選べるかもしれない。しかし、それでも運用上の問いに答えられる環境が必要である。
- 現在の source of truth は何か。
- 最後の action の後に何が変わったか。
- どの checkpoint には証拠があり、どの checkpoint は仮定にすぎないか。
- どの step は安全に retry できるか。
- どの operation は user approval を必要とするか。
- どの artifact を最終結果として引き渡すべきか。
- どの failure は continued execution ではなく recovery を起動すべきか。
これが、仕事を説明できる chatbot と、仕事を届けられる agent system の違いである。
別の SaaSBench からの並行シグナル
似た名前の別の benchmark があり、SaaS-Bench と混同してはならない。coding-oriented な SaaSBench benchmark は、複雑なソフトウェアエンジニアリングタスクに焦点を当てた別の benchmark である。3 報告されている設定には、30 個の complex tasks、5,370 個の validation nodes、8 言語、6 databases、13 frameworks が含まれ、失敗の 95% 超が agents が深い business logic に到達する前に発生している。3
2 つの benchmark は異なる。しかし並行するシグナルは有用だ。環境が専門的な SaaS operations であっても、multi-service software engineering であっても、多くの失敗はシステムが最も深い domain reasoning に到達する前に起きる。Agents は scaffolding で壊れる。setup、state、dependencies、interfaces、validation、recovery である。
これはモデル進歩が無関係だという意味ではない。モデル進歩が何と組み合わされるべきかを変えるのである。
プロダクトレイヤーは Agent Harness になりつつある
Agent 業界は、モデル競争から実行システム競争へ移行している。
優れた harness は単なる tools の集合ではない。Agent work を inspectable かつ governable にする、workspace-level のプロダクトレイヤーである。ユーザーが agent が何をしているのか、すでに何をしたのか、完了を支える evidence は何か、どこに human judgment が必要かを理解できるようにすべきである。
SaaS-Bench 型のワークフローでは、harness layer にいくつかの性質が必要である。
State continuity. 長いワークフローには context stuffing 以上のものが必要だ。システムは user instruction、model hypothesis、observed UI state、saved artifact、verified decision の違いを知る必要がある。
Checkpoint-aware execution. タスクが一連の outcomes に依存するなら、workspace は明示的な verification を促すべきである。部分進捗は可視化されるべきだが、completion と混同されてはならない。
Permission and action boundaries. 専門的な SaaS ワークフローでは、records、invoices、medical administration、team documents、external communication がよく関わる。成熟した agent system には、特に irreversible または externally visible な actions の周辺で、見える approval points と安全な defaults が必要である。
Recovery rather than collapse. UI が変わったり tool が失敗したりしたとき、システムは進捗を hallucinate し続けるべきではない。不確実性を検出し、failure evidence を保持し、安全に retry し、または user に decision を求めるべきである。
Artifact-first output. 専門的な仕事の最終成果は、chat answer であることはまれだ。report、ticket、spreadsheet、submitted form、document revision、media asset、decision record である。Harness はこれらを durable objects として扱うべきである。
Workspace orchestration. 多くのワークフローは 1 つの monolithic thread には広すぎる。Research、execution、verification、final reporting は sessions または workstreams に分離し、workspace-level coordinator が統合できる。
だからこそ “agent harness” と “AI workspace” は収束している。Harness はモデルに hands、guardrails、memory、inspection を与える。Workspace はユーザーに work を supervise、organize、continue する場所を与える。
MCPlato はどこに位置づくか
SaaS-Bench は、ある 1 つの workspace が autonomous SaaS work を解決したという主張として読むべきではない。MCPlato は SaaS-Bench を実行したとも、benchmark の failure modes を排除したとも公に主張していない。責任ある結論はより狭く、より実践的である。この benchmark は、workspace architecture がなぜ重要なのかを検証している。
MCPlato は、本格的な agent work には単一の chat transcript 以上のものが必要だという考えに基づいて設計されている。高いレベルでは、workspaces、sessions、connected materials、visible artifacts、supervised continuation を通じて agent execution を整理する方法をユーザーに提供する。
いくつかの MCPlato の概念は、SaaS-Bench の教訓に自然に対応する。
- Multi-session orchestration. 長い専門的な作業は、research、execution、review、synthesis に分解されることが多い。分離された sessions は境界を保ちながら、ユーザーが全体目標を調整できるようにする。
- Sprite / virtual partner. Workspace-level partner は、何が active で、何が blocked で、何が complete で、何がまだ review を必要とするかを追跡できる。価値は orchestration にあり、演出ではない。
- Artifact discipline. Outputs は、chat flow の外で review できる inspectable deliverables、つまり documents、reports、plans、diagrams、code changes、その他の files になるべきである。
- Local-first connected materials. 実際の work は local documents、project folders、notes、source materials に依存する。これらの materials を task に近い場所に保つ workspace は context loss を減らせる。
- Scheduled and background tasks. 一部の agent work は、単一の同期 chat turn の外で継続する方がよい。特に research、checking、batch production が関係する場合である。
- Permissioned and observable execution. ユーザーはどの actions が試みられたかを見られ、いつ approval が必要かを判断できるべきである。特に agent が external systems や durable artifacts に触れる場合は重要である。
- Decision trace. 長いワークフローには、何が accepted、rejected、deferred され、その理由が何だったかの memory が必要である。その trace がなければ、後の agent step が以前の rationale を誤って取り消す可能性がある。
重要な表現は「整理し、監督するのを助ける」である。Workspace harness は、すべての agent を default で autonomous、correct、safe にするわけではない。ユーザーと agent に、state、artifacts、permissions、recovery が transcript の中に隠れるのではなく product experience の一部になる、より良い execution surface を与える。
SaaS-Bench が示す次の Agent の波
この benchmark は、agent progress のより現実的な定義を示している。
次に有用な agent system は、テキストでどれだけ流暢に推論するかだけでは判断されない。アプリケーションをまたいで continuity を保ち、evidence を保存し、partial failures から recover し、適切なタイミングで permission を求め、専門職が信頼できる artifacts を生成できるかで判断される。
これは「モデルが tools を呼べる」より高い基準である。Tool use は interface にすぎない。プロダクト上の問いは、周囲の harness が長いワークフローにわたって tool use を reliable にできるかどうかである。
SaaS-Bench は、そのギャップを説明するためのより鋭い語彙を業界に与える。
- checkpoint progress は resolved completion と同じではない。
- browser control は professional workflow delivery と同じではない。
- model reasoning は agent execution と同じではない。
- chat transcript は workspace と同じではない。
- observability のない autonomy は product strategy ではない。
結論は、大きなモデルが重要でないということではない。重要である。しかしモデルが改善するにつれ、残る失敗はますます architectural になる。競争の前線は harnesses、workspaces、verification loops、permission models、artifact systems へ移っていく。
モデル競争はまだ続いている。SaaS-Bench は、次の競争が execution-system race であることを示唆している。
References
Footnotes
-
SaaS-Bench arXiv paper および SaaS-Bench HTML version。本記事で引用した title、authors、task composition、multi-application statistics、workflow-step statistics、scoring definitions、Table 2 benchmark scores を含む。 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
Official SaaS-Bench benchmark page and live leaderboard。公式ライブリーダーボードの scores と、記載されている 3,971 weighted checkpoints を含む。 ↩ ↩2 ↩3 ↩4
-
SaaSBench coding benchmark arXiv paper。これは SaaS-Bench とは別の benchmark であり、背景比較シグナルとしてのみ引用している。 ↩ ↩2