為什麼 SaaS-Bench 表明 AI Agent 需要 Harness,而不只是更大的模型
SaaS-Bench 在真實專業 SaaS 工作流中測試 computer-use agents,並揭示了部分進展與已驗證完成之間的差距。結果指向 agent harness、workspace state、verification、permissions 和 recovery 作為下一層產品能力。
發布於 2026-05-25
低於 4%,這是令人不安的頭條結論。
在 SaaS-Bench 論文中,最強的端到端 Resolved Score 仍低於 4%:Table 2 報告 Claude Opus 4.6 的整體 checkpoint score 為 43.2、resolved score 為 1.9,而 GPT-5.4 High 的整體 checkpoint score 為 37.0、resolved score 為 3.8。1 官方即時排行榜應與靜態論文表格分開看待;它同樣顯示,頂尖系統的 checkpoint score 聚集在 40 分出頭,但 resolved score 仍落在 3.8 或 1.9:Claude Opus 4.7 為 43.9 checkpoint / 3.8 resolved,GPT-5.5 High 為 43.8 checkpoint / 1.9 resolved。2
這個差距才是故事本身。Computer-use agents 可以在漫長的 SaaS 工作流中取得可見進展,但它們很少能把工作流一路推進到已驗證完成。瓶頸不只是模型智慧,而是模型周圍缺失的執行系統:state、verification、permissions、recovery、artifacts 和 workspace orchestration。
因此,SaaS-Bench 的價值不在於宣告 agents 很弱,而在於釐清 agents 現在需要哪一種產品層。
SaaS-Bench 測量什麼
SaaS-Bench 的標題是 “SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows?” 作者包括 Kean Shi、Zihang Li、Tianyi Ma、Zengji Tu、Jialong Wu、Xinbo Xu、Qingyao Yang、Ruoyu Wu、Weichu Xie、Ming Wu、Jason Zeng、Michael Heinrich、Elvis Zhang、Liang Chen、Kuan Li 和 Baobao Chang。1
該 benchmark 在 23 個可部署的開源 SaaS 系統上評估 agents,覆蓋 6 個專業領域和 106 項任務。1 這些領域包括 Software Engineering & Project Management、Business Operations & Finance、Healthcare Administration、Team Collaboration & Document Workflow、Artisan Agri-Food Supply Chain,以及 Independent Media Creation。1
這一點很重要。這個 benchmark 不是狹窄的瀏覽器點擊玩具。它更接近人類專業人員在文件、專案看板、儀表板、表單、日曆、財務系統和媒體工具之間切換時所執行的營運性工作。
任務分布讓這一點更加具體。SaaS-Bench 包含 74 個純文字任務和 32 個多模態任務。1 它也強調跨應用工作:106 個任務中有 99 個,也就是 93.4%,涉及至少 2 個應用;53 個任務,也就是 50.0%,涉及 3 個應用。1 工作流也很長:74 個純文字任務中有 72 個,也就是 97.3%,超過 100 步;32 個多模態任務中有 19 個,也就是 61.3%,超過 100 步。1
官方 benchmark 頁面稱,該套件包含 3,971 個加權 verification checkpoints。2 評分設計很關鍵:Checkpoint Score 衡量加權的部分進展,而 Resolved Score 要求某個任務的所有 checkpoints 都通過。2 換句話說,這個 benchmark 不只是問:「agent 看起來忙了嗎?」 它問的是:「專業工作流是否真的以已驗證狀態結束?」
Checkpoint / Resolved 差距是核心訊號
最能說明問題的 SaaS-Bench 結果並不是 agents 得分為零。它們並沒有。更強的系統可以獲得有意義的 checkpoint 分數。它們能夠導航、閱讀、輸入、搜尋、總結,有時還能恢復到足以滿足許多中間條件的狀態。
問題在於,專業工作流具有乘法效應。如果一個任務有許多相互依賴的步驟,少量小缺陷就可能讓最終結果不可用。漏掉一個權限步驟、帶著陳舊 state 繼續、更新了錯誤的 SaaS 記錄、未能驗證上傳的 artifact,或遺失跨應用依賴關係,即使已有可見進展,也可能讓工作流仍未 resolved。
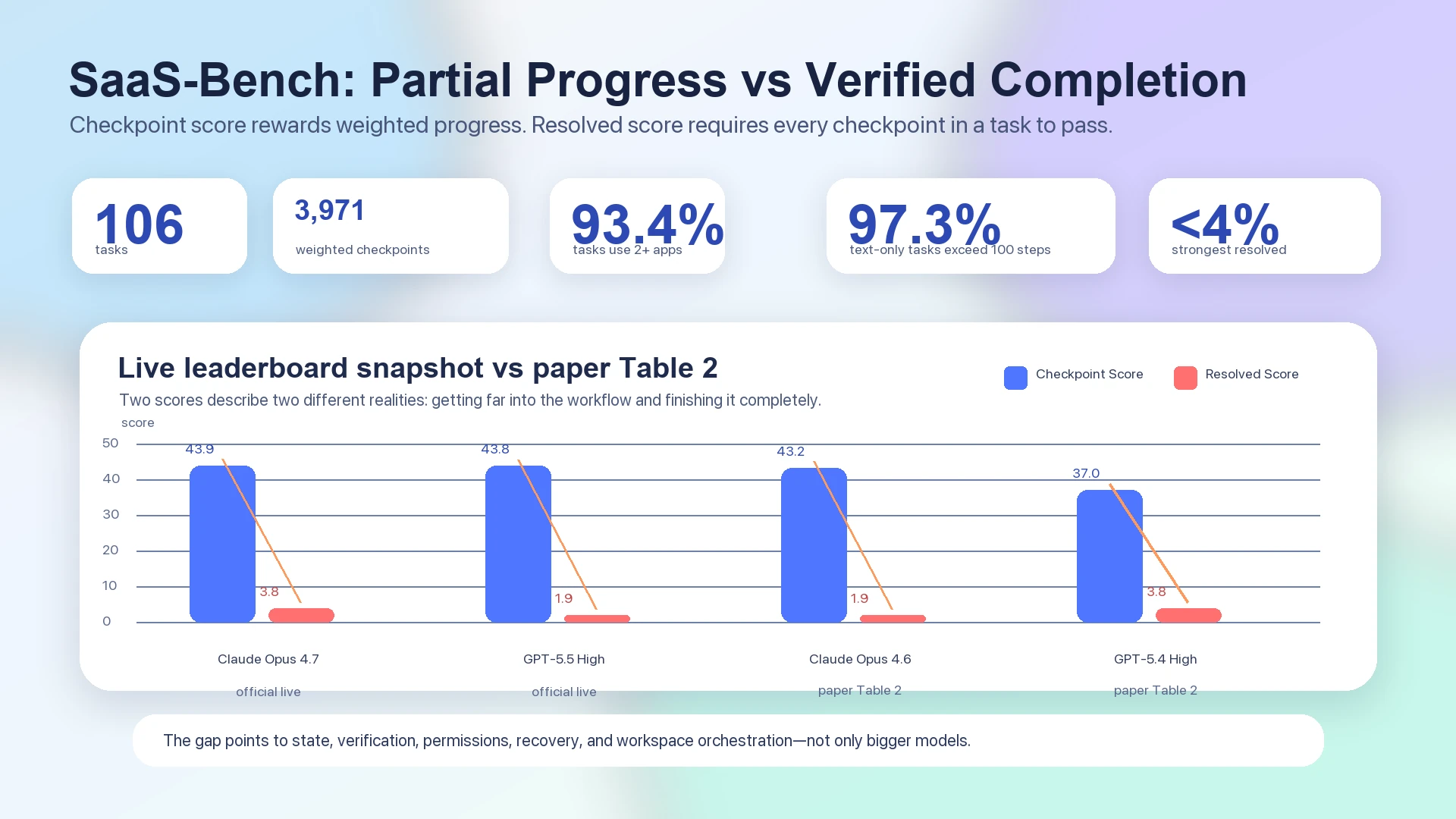 展示 SaaS-Bench 中 checkpoint progress 與 verified completion 差距的資料斷裂圖
展示 SaaS-Bench 中 checkpoint progress 與 verified completion 差距的資料斷裂圖
圖:SaaS-Bench 資料將部分進展與已驗證完成區分開來。論文 Table 2 和官方即時排行榜都顯示,checkpoint scores 遠高於 resolved scores。12
這就是為什麼該 benchmark 更適合用來討論 agent 架構,而不是簡單做模型排名。純 LLM 可以規劃、推理並生成下一步行動。但一個能工作的 agent 還必須在許多步驟之間保存 state,驗證外部世界是否按預期變化,知道何時請求 permission,安全重試,並留下可檢查的 artifacts。
模型是推理引擎。Harness 是執行系統。
LLM 不等於 Agent
「AI agent」這個短語常常把多個層次壓縮成一個詞。SaaS-Bench 讓這種壓縮更難成立。
語言模型可以生成這樣的計畫:「開啟 CRM,更新客戶記錄,附上已簽署文件,通知團隊,並核對發票。」 但專業工作流需要的不只是計畫。系統必須知道哪個瀏覽器 state 是目前的,哪個 SaaS app 是權威來源,哪個檔案是記錄中的 artifact,哪個動作可逆,哪個動作需要使用者批准,以及哪個 checkpoint 能證明任務已經完成。
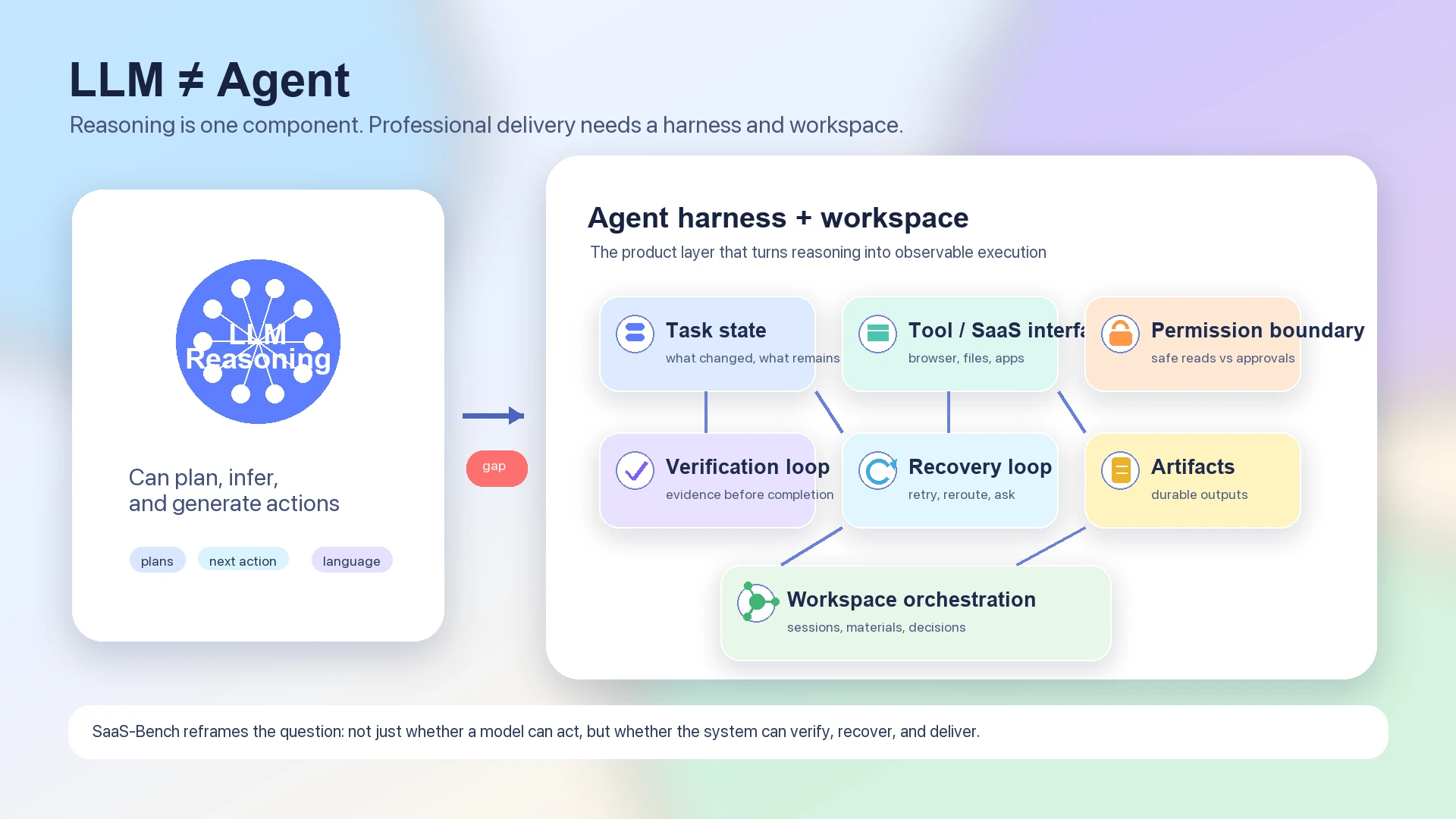 LLM 是更大 agent harness 與 workspace architecture 中的一個組成部分
LLM 是更大 agent harness 與 workspace architecture 中的一個組成部分
因此,一個有用的 agent stack 至少包含這些層:
| 層 | 貢獻 |
|---|---|
| LLM reasoning | 解讀目標、起草計畫、選擇下一步行動,並解釋權衡。 |
| Task state | 追蹤已完成事項、仍待處理事項,以及哪些假設尚未驗證。 |
| Tool and SaaS interface | 將瀏覽器操作、文件、檔案、SaaS 系統和外部工具連接成可用能力。 |
| Permission boundary | 區分安全的唯讀操作與需要明確批准或監督的操作。 |
| Verification loop | 檢查每個重要 state transition 是否真的發生。 |
| Recovery loop | 處理失敗、重試、部分完成、UI state 變化和意外結果。 |
| Artifact discipline | 產出持久的文件、記錄、表格、ticket、報告或程式碼變更,而不只是 chat replies。 |
| Workspace orchestration | 隨時間協調多個 sessions、materials、decisions 和 follow-up tasks。 |
當這些層較弱時,更強的模型仍可能失敗。它可能在抽象層面推理正確,卻隨後失去對具體世界的追蹤。它可能完成了大多數可見步驟,卻仍漏掉定義成功的那個驗證條件。它可能具備長推理能力,卻缺少用於長期執行工作的安全機制。
SaaS-Bench 間接測量了這些缺失層。Checkpoint score 表明模型可以做出貢獻。Resolved score 表明僅有這種貢獻還不夠。
失敗不只是「模型智慧」問題
人們很容易把 benchmark 表格解讀為模型競賽。這部分成立,但並不完整。
對於短任務,模型品質可能占主導。如果工作只是一次性回答,最強的推理模型通常會勝出。對於漫長的 SaaS 工作流,失敗分布會改變。Agent 必須在一個有 state、有 permissions、非同步且不一致的世界裡行動。瀏覽器可能沒有顯示預期元素。文件可能被儲存到錯誤位置。SaaS 表單可能需要隱藏驗證。通知可能必須引用正確的 artifact。某個工作流可能要求在後續步驟改變所需輸出後,回到之前的 app。
這些既是 harness 問題,也是推理問題。
更強的模型也許能選擇更好的動作,但它仍然需要一個能夠回答營運性問題的環境:
- 目前的 source of truth 是什麼?
- 上一個動作之後發生了什麼變化?
- 哪個 checkpoint 有證據,哪個 checkpoint 只是被假定完成?
- 哪一步可以安全重試?
- 哪個操作需要使用者批准?
- 哪個 artifact 應該作為最終結果移交?
- 哪種失敗應該觸發 recovery,而不是繼續執行?
這就是能夠描述工作的 chatbot 與能夠交付工作的 agent system 之間的區別。
來自另一個 SaaSBench 的平行訊號
還有另一個名稱相似的 benchmark,不應與 SaaS-Bench 混淆。面向 coding 的 SaaSBench benchmark 是一個不同的 benchmark,聚焦複雜軟體工程任務。3 其報告的設定包括 30 個複雜任務、5,370 個 validation nodes、8 種語言、6 個資料庫和 13 個框架,並且超過 95% 的失敗發生在 agents 觸及深層業務邏輯之前。3
兩個 benchmark 並不相同,但這個平行訊號很有用。無論環境是專業 SaaS 營運,還是多服務軟體工程,許多失敗都發生在系統觸及最深層領域推理之前。Agents 會在腳手架層面出問題:setup、state、dependencies、interfaces、validation 和 recovery。
這並不意味著模型進步無關緊要。它改變的是模型進步必須與什麼配套。
產品層正在變成 Agent Harness
Agent 行業正在從模型競賽轉向執行系統競賽。
一個好的 harness 不只是工具集合。它是 workspace 級別的產品層,使 agent work 可檢查、可治理。它應該幫助使用者理解 agent 正在做什麼、已經做了什麼、哪些證據支持完成,以及哪些地方需要人類判斷。
對於 SaaS-Bench 這類工作流,harness 層需要具備幾項屬性。
State continuity. 長工作流需要的不只是 context stuffing。系統需要知道使用者指令、模型假設、已觀察到的 UI state、已保存 artifact 和已驗證 decision 之間的區別。
Checkpoint-aware execution. 如果任務依賴一系列結果,workspace 應鼓勵明確驗證。部分進展應該可見,但不應與完成混淆。
Permission and action boundaries. 專業 SaaS 工作流通常涉及記錄、發票、醫療行政、團隊文件或外部溝通。成熟的 agent system 需要可見的 approval points 和安全預設值,尤其是在不可逆或對外可見的動作周圍。
Recovery rather than collapse. 當 UI 變化或工具失敗時,系統不應只是繼續幻覺式地推進進度。它應該偵測不確定性,保留失敗證據,安全重試,或向使用者請求決策。
Artifact-first output. 專業工作的最終產物很少是 chat answer。它可能是報告、ticket、spreadsheet、已提交表單、文件修訂、媒體資產或決策記錄。Harness 應該把這些視為持久物件。
Workspace orchestration. 許多工作流對一個單體執行緒來說過於寬泛。Research、execution、verification 和 final reporting 可以拆分為 sessions 或 workstreams,再由 workspace 級 coordinator 進行協調。
這就是為什麼「agent harness」與「AI workspace」正在融合。Harness 給模型提供雙手、guardrails、memory 和 inspection。Workspace 給使用者一個監督、組織並延續工作的地方。
MCPlato 適合放在哪裡
不應把 SaaS-Bench 解讀為某個 workspace 已經解決了自主 SaaS 工作。MCPlato 並未公開聲稱執行過 SaaS-Bench,也未聲稱消除了該 benchmark 的失敗模式。更負責的結論更窄,也更實際:這個 benchmark 驗證了為什麼 workspace architecture 很重要。
MCPlato 的設計圍繞一個理念:嚴肅的 agent work 需要的不只是單一 chat transcript。從高層看,它為使用者提供了一種透過 workspaces、sessions、connected materials、visible artifacts 和 supervised continuation 來組織 agent execution 的方式。
幾個 MCPlato 概念可以自然映射到 SaaS-Bench 的啟示:
- Multi-session orchestration. 漫長的專業工作通常會拆分為 research、execution、review 和 synthesis。分離的 sessions 有助於保持邊界,同時仍允許使用者協調總體目標。
- Sprite / virtual partner. Workspace 級 partner 可以幫助追蹤什麼在進行中、什麼被阻塞、什麼已完成、什麼仍需 review。價值在於 orchestration,而不是表演性。
- Artifact discipline. 輸出應成為可檢查的 deliverables:documents、reports、plans、diagrams、code changes,或其他可在 chat flow 之外審查的檔案。
- Local-first connected materials. 真實工作依賴本地文件、專案資料夾、筆記和來源材料。讓這些 materials 貼近任務的 workspace 可以減少 context loss。
- Scheduled and background tasks. 某些 agent work 適合在單個同步 chat turn 之外繼續,尤其是在涉及 research、checking 或 batch production 時。
- Permissioned and observable execution. 使用者應該能看到哪些 actions 已經被嘗試,並決定某一步何時需要 approval,尤其是在 agent 接觸 external systems 或 durable artifacts 時。
- Decision trace. 長工作流需要記住什麼被接受、拒絕、延期以及原因。沒有這條 trace,後續 agent 步驟可能會意外推翻早先步驟的理由。
關鍵措辭是「幫助組織和監督」。Workspace harness 並不會讓每個 agent 預設變得自主、正確或安全。它為使用者和 agent 提供了更好的執行表面:state、artifacts、permissions 和 recovery 成為產品體驗的一部分,而不是隱藏在 transcript 裡。
SaaS-Bench 暗示下一波 Agent 會是什麼樣
這個 benchmark 指向了一個更現實的 agent progress 定義。
下一代有用的 agent system 不會只按它在文字中推理得多流暢來判斷。它會按是否能夠跨應用保持 continuity、保存 evidence、從部分失敗中 recovery、在正確時間請求 permission,並產出專業人員可以信任的 artifacts 來判斷。
這比「模型可以呼叫工具」門檻更高。Tool use 只是介面。產品問題在於周圍的 harness 是否能讓 tool use 在長工作流中變得可靠。
SaaS-Bench 給行業提供了更清晰的詞彙來描述這個差距:
- checkpoint progress 不等於 resolved completion;
- browser control 不等於 professional workflow delivery;
- model reasoning 不等於 agent execution;
- chat transcript 不等於 workspace;
- 沒有 observability 的 autonomy 不是產品策略。
結論並不是更大的模型不重要。它們當然重要。但隨著模型改進,剩餘失敗越來越具有架構屬性。競爭前沿正在轉向 harnesses、workspaces、verification loops、permission models 和 artifact systems。
模型競賽仍在繼續。SaaS-Bench 暗示,下一場競賽是執行系統競賽。
參考資料
Footnotes
-
SaaS-Bench arXiv 論文和 SaaS-Bench HTML 版本,包括本文引用的標題、作者、任務組成、跨應用統計、工作流步驟統計、評分定義以及 Table 2 benchmark scores。 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
SaaS-Bench 官方 benchmark 頁面與即時排行榜,包括官方即時排行榜分數以及所述的 3,971 個加權 checkpoints。 ↩ ↩2 ↩3 ↩4
-
SaaSBench coding benchmark arXiv 論文。這是一個不同於 SaaS-Bench 的 benchmark;本文僅將其作為背景對比訊號引用。 ↩ ↩2