Comment utiliser des agents IA generaux sans perdre le controle
Les agents IA generaux sont les plus utiles lorsqu'ils fonctionnent dans des workflows bornes et inspectables. Ce guide couvre les contrats de prompt, la structure des taches longues, les points de controle humains, les environnements selectionnes et les artefacts revisables pour des agents comme Hermes, des passerelles de style OpenClaw et MCPlato.
La plupart des gens ne perdent pas le controle d'un agent IA general parce que le prompt est trop court. Ils le perdent parce que le travail n'a jamais ete modele comme un workflow controlable.
Un agent general n'est pas seulement un assistant de codage. Il peut faire de la recherche, piloter un navigateur, resumer des documents, planifier du travail, coordonner des sous-taches, preparer des artefacts ou agir dans un espace de travail. Des outils comme Hermes, des passerelles proches d'OpenClaw et MCPlato indiquent ce modele plus large : un partenaire IA capable d'utiliser des outils et du contexte dans la duree. La documentation publique d'OpenClaw reste fortement orientee vers les workflows d'agents de codage. Il vaut donc mieux le traiter ici comme un exemple de frontiere et de passerelle, plutot que comme un manuel complet pour agents generaux.
La question pratique n'est donc pas : "Comment ecrire un prompt plus elegant ?" Elle est : Comment concevoir un travail borne et inspectable afin qu'un agent puisse aider sans prendre silencieusement le controle ?
Voici cinq pratiques qui rendent les agents generaux plus fiables pour le travail de connaissance, les operations, la recherche et l'execution en plusieurs etapes.
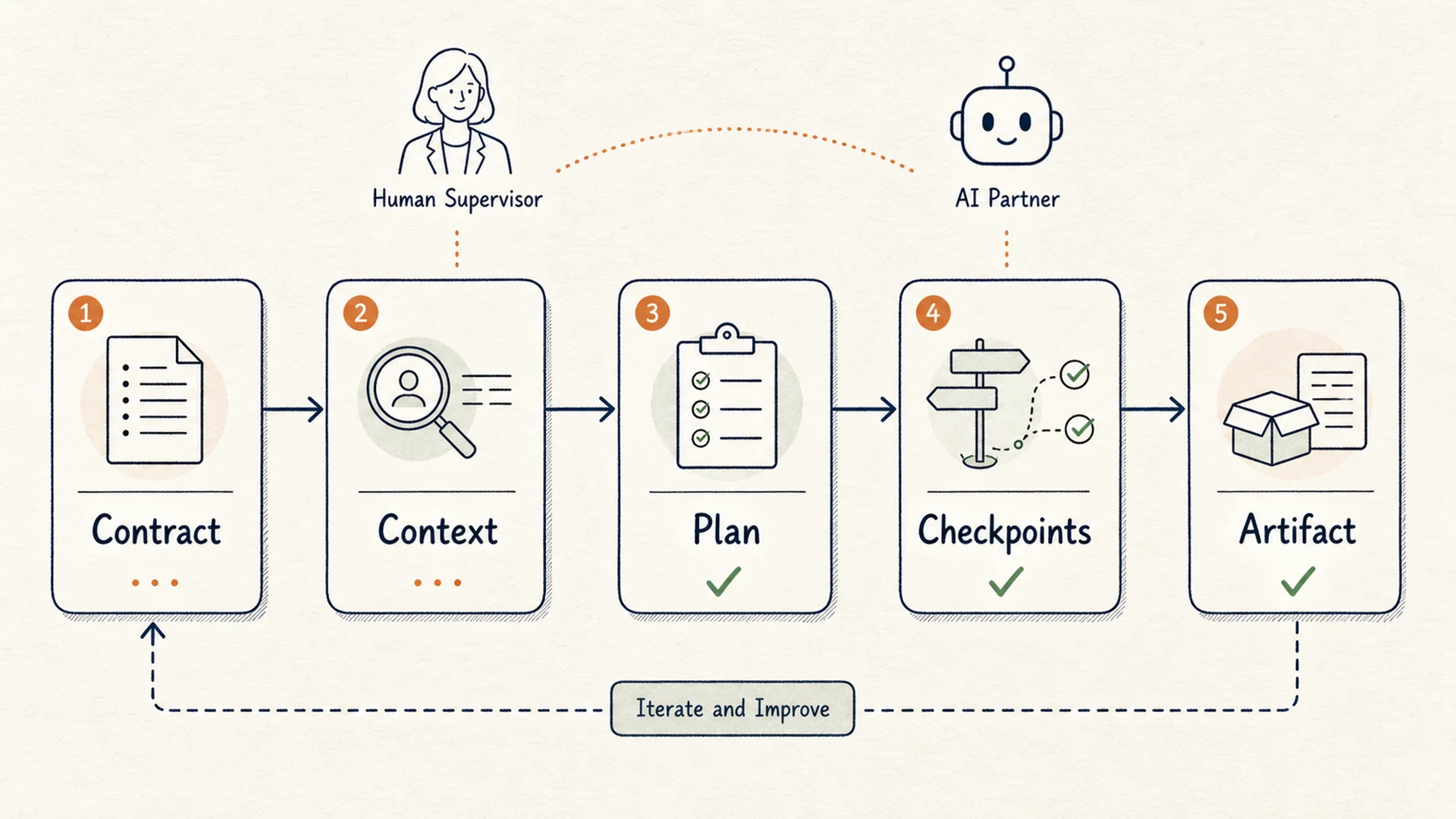 Schema d'un workflow borne pour utiliser des agents IA generaux
Schema d'un workflow borne pour utiliser des agents IA generaux
1. Ecrivez un contrat de prompt, pas un souhait
Une instruction faible ressemble a ceci :
Fais des recherches sur ce sujet et produis un bon rapport.
Une instruction plus forte fonctionne comme un contrat operationnel. Elle indique a l'agent ce que signifie le succes, ou sont les limites, quelles preuves sont requises et quand l'agent doit s'arreter.
Un prompt utile pour un agent general devrait generalement inclure :
| Champ du contrat | Ce qu'il faut specifier |
|---|---|
| Objectif | Le resultat dont l'utilisateur a vraiment besoin, pas seulement l'activite. |
| Criteres de succes | Ce qui doit etre vrai pour que la tache soit consideree comme terminee. |
| Conditions d'echec | Quand s'arreter, escalader ou signaler une incertitude. |
| Materiaux d'entree | Quels fichiers, liens, notes, jeux de donnees ou decisions precedentes font autorite. |
| Outils et outils interdits | Ce que l'agent peut utiliser, et ce qu'il ne doit pas utiliser. |
| Actions de confirmation | Quelles actions exigent une approbation avant execution. |
| Points de controle | Ou l'agent doit faire une pause et resumer la progression. |
| Artefact final | Le livrable attendu : memo, tableau, deck, ticket, plan, feuille de calcul, image ou journal de decision. |
| Preuves | Citations, journaux, captures d'ecran, resultats de tests, chemins de fichiers ou hypotheses qui soutiennent le resultat. |
Ce cadrage est coherent avec les recommandations de prompt d'AWS, qui mettent l'accent sur des objectifs clairs, les contraintes de tache et les sorties attendues, ainsi qu'avec les conseils d'Anthropic sur la construction d'agents efficaces, ou les agents fonctionnent mieux lorsque les workflows sont composes deliberement au lieu d'etre laisses a une autonomie vague.
Le but n'est pas de rendre chaque prompt long. Le but est de rendre le contrat operationnel explicite. Les prompts courts conviennent aux taches courtes. Les agents de longue duree qui utilisent des outils ont besoin de contrats.
2. Decoupez le travail long en plans, points de controle et etats de reprise
Les agents generaux deviennent fragiles lorsqu'on leur demande de porter une longue mission comme un fil mental ininterrompu. Le travail long devrait etre structure comme une sequence d'etats inspectables :
- Plan : Ce qui sera fait, dans quel ordre et pourquoi.
- Sous-taches : Unites de travail assez petites pour etre verifiees.
- Points de controle : Endroits ou l'utilisateur ou le systeme peut inspecter la progression.
- Reprise : Un moyen de reprendre, reessayer ou revenir en arriere apres une interruption.
- Synthese finale : Un artefact durable qui resume ce qui a change et ce qui reste ouvert.
Le modele orchestrator-workers d'Anthropic est utile ici : un agent coordinateur divise la tache en parties, tandis que des worker specialises traitent des sous-taches bornees. Les modeles de persistance et d'interruptions de LangGraph montrent la meme idee architecturale sous un autre angle : les agents de longue duree ont besoin d'etat, de points de controle et de la capacite de faire une pause avant les actions sensibles.
Hermes illustre aussi pourquoi les environnements d'agents generaux ont besoin de memoire durable, d'automatisations planifiees, de sous-agents isoles et de limites d'outils. Ce ne sont pas des fonctions decoratives. Ce sont elles qui permettent a un agent de survivre a un travail couvrant de nombreuses etapes, plusieurs sessions ou une execution en arriere-plan.
Dans MCPlato, le meme principe apparait sous forme de coordination au niveau de l'espace de travail : plusieurs sessions peuvent porter differentes parties du travail, un partenaire virtuel ou Sprite peut coordonner la progression, les materiaux connectes peuvent rester local-first, et les taches planifiees ou en arriere-plan peuvent continuer sans tout reduire a un seul historique de chat. Cela ne fait pas de MCPlato un substitut magique a la conception de processus. Cela rend simplement cette conception plus facile a conserver.
3. Placez la revue humaine aux frontieres de risque, pas a chaque clic
Le controle human-in-the-loop est souvent mal compris. Si un utilisateur doit approuver chaque minuscule etape, l'agent devient plus lent que le travail manuel. Si l'agent peut tout faire sans revue, l'utilisateur n'a pas de controle reel.
Le meilleur modele est une echelle de risque.
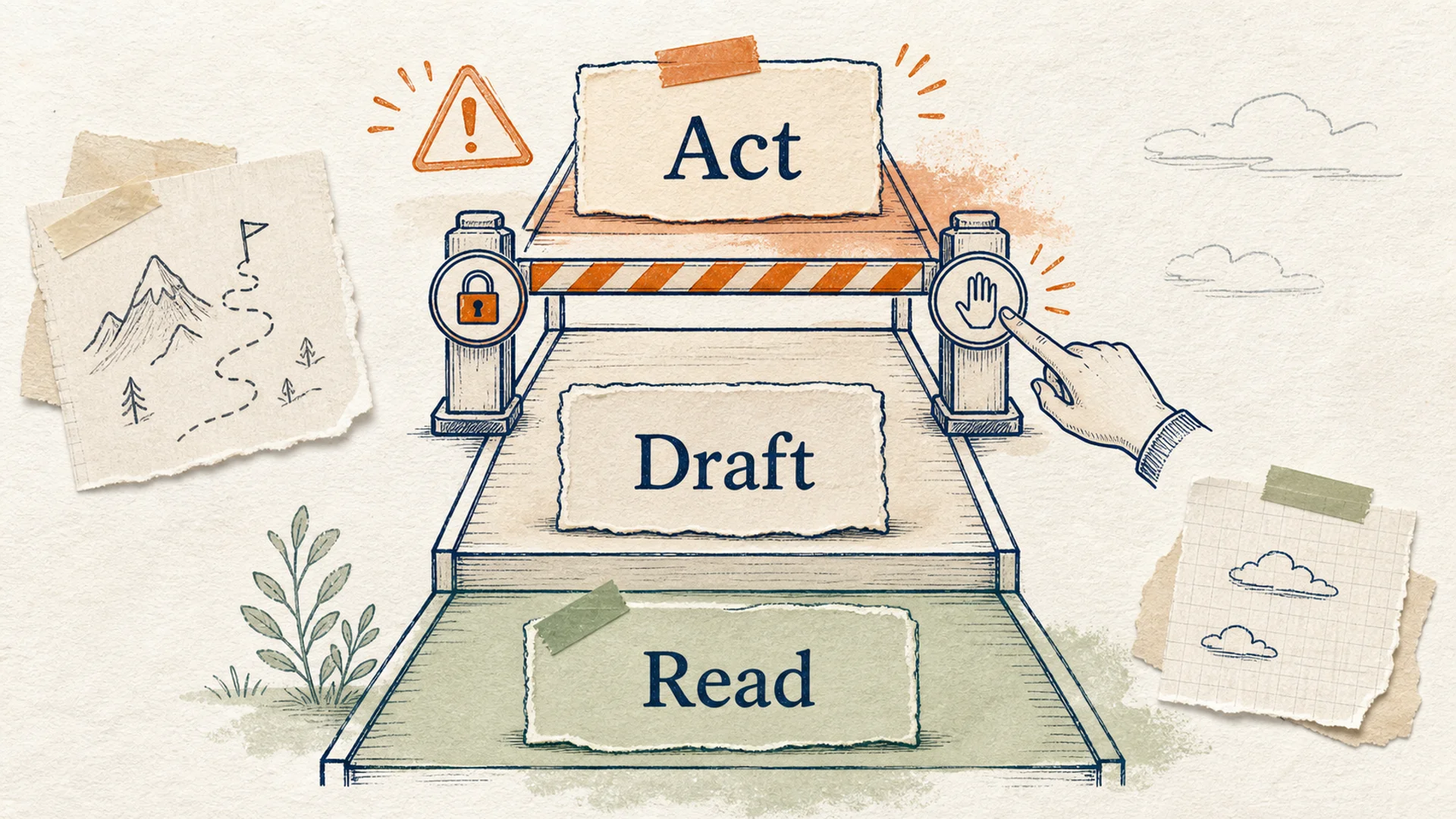 Echelle de risque montrant ou la confirmation humaine devrait intervenir
Echelle de risque montrant ou la confirmation humaine devrait intervenir
Les actions a faible risque peuvent generalement avancer avec une supervision legere :
- lire les materiaux fournis ;
- chercher dans un espace de travail approuve ;
- rediger un plan ;
- resumer des sources ;
- proposer les prochaines etapes.
Les actions a risque moyen devraient produire un point de controle :
- modifier un document ;
- generer un brouillon destine a un client ;
- creer une liste de taches ;
- preparer une transformation de donnees ;
- recommander une decision.
Les actions a risque eleve devraient exiger une confirmation explicite :
- envoyer un message a l'exterieur ;
- supprimer ou ecraser des donnees ;
- acheter, publier, deployer ou soumettre ;
- acceder a des systemes sensibles ;
- effectuer des actions difficiles a annuler.
Cela correspond a la direction des travaux d'Anthropic sur les agents fiables et l'utilisation de l'ordinateur, aux controles human-in-the-loop de l'OpenAI Agents SDK, et aux recommandations Microsoft Responsible AI : la supervision devrait etre liee au risque, a l'autorite, a la reversibilite et a l'impact.
Une bonne instruction n'est donc pas "demande-moi avant de faire quoi que ce soit". Elle est plus precise :
Tu peux lire et resumer tous les materiaux fournis. Tu peux rediger des fichiers. Avant d'envoyer des messages, de supprimer des fichiers, de modifier des permissions, de publier ou de faire des modifications irreversibles, arrete-toi et demande confirmation avec une breve explication du risque.
Ce type de limite permet a l'agent de rester utile tout en preservant l'autorite humaine.
4. Selectionnez l'environnement de l'agent avant d'augmenter son autonomie
Lorsqu'un agent general fonctionne mal, les utilisateurs essaient souvent de corriger le probleme en ajoutant plus d'instructions. Parfois, le vrai probleme est l'environnement.
Les agents ont besoin d'une surface operationnelle selectionnee :
- Materiaux faisant autorite : Indiquez a l'agent quels fichiers, liens, notes ou depots comptent le plus.
- Permissions minimales necessaires : Donnez l'acces en lecture avant l'ecriture ; l'acces local avant l'acces externe ; les actions reversibles avant les actions irreversibles.
- Zones d'execution sures : Utilisez des sandboxes, brouillons, environnements de staging ou espaces de travail isoles pour le travail risque.
- Frontieres reseau claires : Definissez les sources autorisees, bloquees ou preferees.
- Sortie d'outil a fort signal : Les outils devraient renvoyer des resultats structures, concis et actionnables, plutot que des dumps bruyants.
- Contexte persistant : Les decisions importantes, hypotheses et artefacts devraient survivre au tour de chat.
Les conseils d'Anthropic sur l'utilisation de l'ordinateur et l'ecriture d'outils reviennent sans cesse a la meme idee : la qualite d'un agent depend fortement des outils et de l'environnement qui l'entourent. AWS presente aussi les agents d'utilisation de l'ordinateur comme des systemes qui doivent gerer l'execution des taches, les outils et les contraintes de securite, pas seulement des prompts.
Pour les agents generaux, cela compte encore plus que pour les agents de codage etroits. Un assistant de codage vit souvent dans un depot avec des tests, des diffs et un controle de version. Un agent general peut operer a travers des documents, calendriers, onglets de navigateur, messages, PDF, notes et politiques internes. Sans environnement selectionne, l'agent doit deviner ce qui compte.
Les materiaux connectes local-first de MCPlato sont une facon de rendre cela gerable : l'utilisateur peut attacher le repertoire, les fichiers ou le contexte projet pertinents, puis laisser les sessions d'agent travailler dans cette frontiere selectionnee. Le principe important est portable : ne demandez pas a un agent d'etre autonome dans un environnement que vous n'avez pas prepare.
5. Demandez des artefacts revisables, pas seulement des reponses de chat
Le resultat final du travail d'un agent devrait generalement etre quelque chose que l'utilisateur peut inspecter sans rejouer toute la conversation.
Par exemple :
| Type de tache | Sortie faible | Meilleur artefact |
|---|---|---|
| Recherche | "Voici ce que j'ai trouve." | Une note sourcee avec affirmations, citations et questions ouvertes. |
| Operations | "J'ai termine la tache." | Une checklist avec actions realisees, fichiers modifies et points non resolus. |
| Planification | "Voici un plan." | Un plan par jalons avec responsables, dependances, risques et points de decision. |
| Contenu | "Voici un brouillon." | Un document avec structure, references, images et notes de revision. |
| Travail de donnees | "Les donnees sont nettoyees." | Une feuille de calcul ou un tableau avec notes de transformation et controles de validation. |
Le travail artifact-first devient un modele produit courant. Claude Artifacts a rendu les sorties durables plus visibles pour les utilisateurs. OpenAI tracing et LangSmith observability montrent le besoin operationnel voisin : lorsque les agents agissent, les equipes ont besoin de traces, de preuves et d'un etat inspectable. Les recommandations Microsoft Responsible AI mettent aussi l'accent sur la responsabilite, la surveillance, la gouvernance et la supervision humaine.
Pour un agent general, l'artefact n'est pas une decoration. C'est la surface de controle. Il permet a l'utilisateur de demander :
- Qu'est-ce que l'agent a reellement produit ?
- Quelles sources ou quels outils l'ont soutenu ?
- Quelles decisions ont ete prises ?
- Quelles actions restent en attente ?
- Que devrait revoir un humain avant l'etape suivante ?
La discipline d'artefacts et les traces de decision de MCPlato s'inscrivent naturellement dans ce modele : la valeur ne tient pas seulement au fait qu'un partenaire IA peut aider au travail, mais au fait que le travail peut devenir visible, reprenable et revisable d'une session a l'autre.
Un modele de depart pratique
Si vous voulez un prompt reutilisable pour un agent general, commencez par ceci :
Objectif :
[Decrivez le resultat reel, pas seulement l'activite.]
Contexte et materiaux :
[Joignez ou listez les fichiers, liens, notes et contraintes faisant autorite.]
Criteres de succes :
[Definissez ce qui doit etre vrai a la fin.]
Limites :
[Outils autorises, outils interdits, limites de donnees, limites reseau et regles de permission.]
Workflow :
1. Reformuler l'objectif et les hypotheses.
2. Proposer un plan court.
3. Executer en petites sous-taches.
4. Faire une pause aux points de controle suivants : [lister les points de controle].
5. Demander confirmation avant : [actions a haut risque].
Preuves :
[Exiger citations, journaux, captures d'ecran, chemins de fichiers, diffs ou notes de validation.]
Artefact final :
[Specifier le format du livrable et ou il doit etre enregistre ou affiche.]
En cas de blocage :
[Signaler le blocage, ce qui a ete essaye et l'option suivante la plus sure.]
Ce modele est volontairement simple. Il fonctionne parce qu'il transforme l'usage d'un agent, d'une delegation ouverte, en collaboration bornee.
Conclusion : le controle est une propriete du workflow
Les agents generaux ne deviendront pas fiables par les prompts seuls. Ils ont besoin de contrats clairs, de contexte selectionne, de limites de permission, de points de controle, de chemins de reprise et d'artefacts durables.
C'est vrai que l'agent soit une automatisation de style Hermes, une passerelle proche d'OpenClaw, le modele de partenaire IA multi-session de MCPlato, ou un autre environnement d'agent general. Le modele gagnant n'est pas l'autonomie maximale. C'est l'autonomie bornee avec inspection.
Lorsque les utilisateurs conçoivent le workflow, les agents peuvent agir avec plus de confiance. Lorsque les utilisateurs sautent le workflow, meme un agent capable devient une source tres rapide d'incertitude.
Références
- AWS Prescriptive Guidance : agents d'utilisation de l'ordinateur
- AWS Connect : bonnes pratiques de prompt pour le self-service agentique
- Anthropic : construire des agents efficaces
- Persistance LangGraph
- Interruptions LangGraph
- Documentation Hermes
- Anthropic : vers des agents IA fiables
- Documentation de l'outil Claude computer use
- OpenAI Agents SDK : humain dans la boucle
- Microsoft : Responsible AI pour les agents dans toute l'organisation
- Anthropic Engineering : ecrire des outils pour les agents
- Documentation OpenClaw
- Claude Artifacts
- OpenAI Agents SDK : Tracing
- LangSmith observability
- MCPlato