Pourquoi SaaS-Bench montre que les AI Agents ont besoin de Harnesses, pas seulement de modèles plus grands
SaaS-Bench teste des computer-use agents sur de véritables workflows SaaS professionnels et expose l'écart entre progression partielle et achèvement vérifié. Le résultat désigne les agent harnesses, workspace state, verification, permissions et recovery comme la prochaine couche produit.
Publié le 2026-05-25
Moins de quatre pour cent : voilà le titre inconfortable.
Dans le paper SaaS-Bench, le meilleur Resolved Score end-to-end reste sous les quatre pour cent : Claude Opus 4.6 est indiqué avec un overall checkpoint score de 43.2 et un resolved score de 1.9 dans la Table 2, tandis que GPT-5.4 High est indiqué avec un overall checkpoint score de 37.0 et un resolved score de 3.8.1 Le live leaderboard officiel, qui doit être traité séparément de la table statique du paper, montre aussi des systèmes de tête regroupés autour du bas des quarante en checkpoint score, tout en restant à 3.8 ou 1.9 en resolved score : Claude Opus 4.7 à 43.9 checkpoint / 3.8 resolved, et GPT-5.5 High à 43.8 checkpoint / 1.9 resolved.2
Cet écart est l'histoire centrale. Les computer-use agents peuvent produire des progrès visibles dans de longs workflows SaaS, mais ils portent rarement le workflow jusqu'à un achèvement vérifié. Le goulot d'étranglement n'est pas seulement l'intelligence du modèle. C'est le système d'exécution manquant autour du modèle : state, verification, permissions, recovery, artifacts et workspace orchestration.
SaaS-Bench est donc utile non pas parce qu'il déclare que les agents sont faibles, mais parce qu'il clarifie le type de couche produit dont les agents ont désormais besoin.
Ce que mesure SaaS-Bench
SaaS-Bench s'intitule “SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows?” Il a été rédigé par Kean Shi, Zihang Li, Tianyi Ma, Zengji Tu, Jialong Wu, Xinbo Xu, Qingyao Yang, Ruoyu Wu, Weichu Xie, Ming Wu, Jason Zeng, Michael Heinrich, Elvis Zhang, Liang Chen, Kuan Li et Baobao Chang.1
Le benchmark évalue des agents sur 23 systèmes SaaS open-source déployables, dans 6 domaines professionnels et 106 tâches.1 Ces domaines sont Software Engineering & Project Management, Business Operations & Finance, Healthcare Administration, Team Collaboration & Document Workflow, Artisan Agri-Food Supply Chain et Independent Media Creation.1
C'est important. Le benchmark n'est pas un simple jouet de clics dans le navigateur. Il est plus proche du travail opérationnel que des professionnels humains effectuent lorsqu'ils passent entre documents, project boards, dashboards, formulaires, calendriers, systèmes financiers et outils média.
La distribution des tâches rend cela concret. SaaS-Bench inclut 74 text-only tasks et 32 multimodal tasks.1 Il met aussi l'accent sur le cross-application work : 99 tâches sur 106, soit 93.4%, impliquent au moins 2 applications, tandis que 53 tâches, soit 50.0%, impliquent 3 applications.1 Les workflows sont longs également : 72 des 74 text-only tasks, soit 97.3%, dépassent 100 étapes, et 19 des 32 multimodal tasks, soit 61.3%, dépassent 100 étapes.1
La page officielle du benchmark indique que la suite contient 3,971 weighted verification checkpoints.2 La conception du scoring est importante : Checkpoint Score mesure une progression partielle pondérée, tandis que Resolved Score exige que tous les checkpoints d'une tâche réussissent.2 Autrement dit, le benchmark ne demande pas seulement : « L'agent a-t-il eu l'air occupé ? » Il demande : « Le workflow professionnel s'est-il réellement terminé dans un état vérifié ? »
L'écart Checkpoint / Resolved est le signal central
Le résultat le plus révélateur de SaaS-Bench n'est pas que les agents obtiennent zéro. Ce n'est pas le cas. Les systèmes plus forts collectent un crédit checkpoint significatif. Ils peuvent naviguer, lire, saisir, chercher, résumer et parfois récupérer assez pour satisfaire de nombreuses conditions intermédiaires.
Le problème est que les workflows professionnels sont multiplicatifs. Si une tâche comporte de nombreuses étapes dépendantes, quelques petits défauts peuvent rendre le résultat final inutilisable. Oublier une permission step, transporter un state obsolète, mettre à jour le mauvais SaaS record, ne pas valider un artifact téléversé ou perdre une cross-app dependency peut laisser le workflow unresolved malgré des progrès visibles.
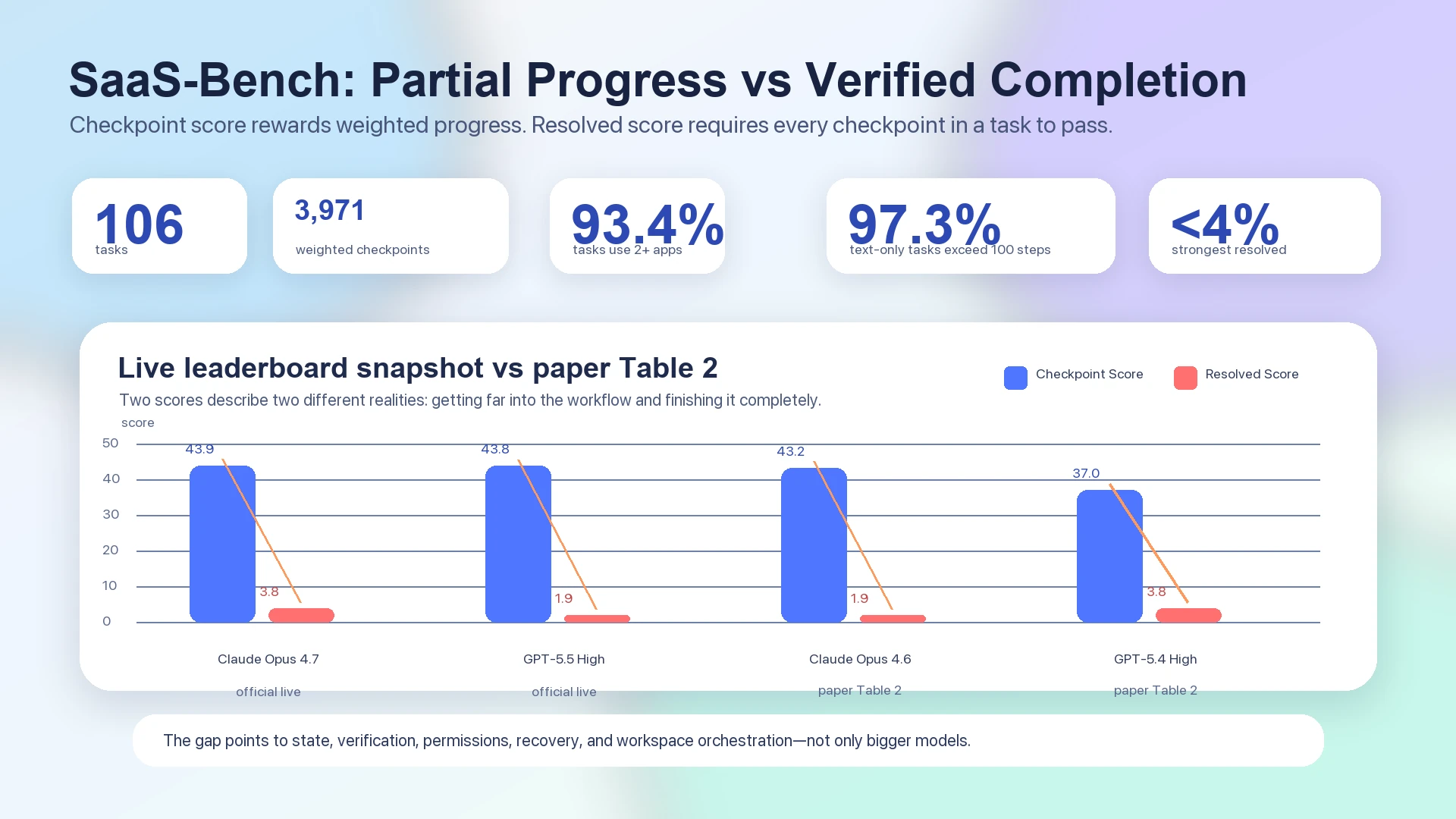 Un diagramme de fracture des données montre l’écart SaaS-Bench entre checkpoint progress et verified completion
Un diagramme de fracture des données montre l’écart SaaS-Bench entre checkpoint progress et verified completion
Figure : Les données de SaaS-Bench séparent la progression partielle de l’achèvement vérifié. La Table 2 du paper et le live leaderboard officiel montrent tous deux des checkpoint scores beaucoup plus élevés que les resolved scores.12
C'est pourquoi le benchmark convient mieux à une discussion sur l'agent architecture qu'à un simple classement de modèles. Un LLM pur peut planifier, raisonner et générer les prochaines actions. Mais un agent opérationnel doit aussi préserver le state sur de nombreuses étapes, vérifier si le monde a changé comme prévu, savoir quand demander une permission, réessayer en sécurité et laisser derrière lui des artifacts inspectables.
Le modèle est le moteur de raisonnement. Le harness est le système d'exécution.
LLM ne veut pas dire Agent
L'expression « AI agent » fusionne souvent plusieurs couches en un seul mot. SaaS-Bench rend cette fusion plus difficile à défendre.
Un modèle de langage peut produire un plan comme « ouvrir le CRM, mettre à jour la fiche client, joindre le document signé, notifier l'équipe et rapprocher la facture ». Mais le workflow professionnel exige plus qu'un plan. Il exige que le système sache quel browser state est courant, quelle SaaS app fait autorité, quel fichier est l'artifact of record, quelle action est réversible, quelle action demande une user approval et quel checkpoint prouve que la tâche est complète.
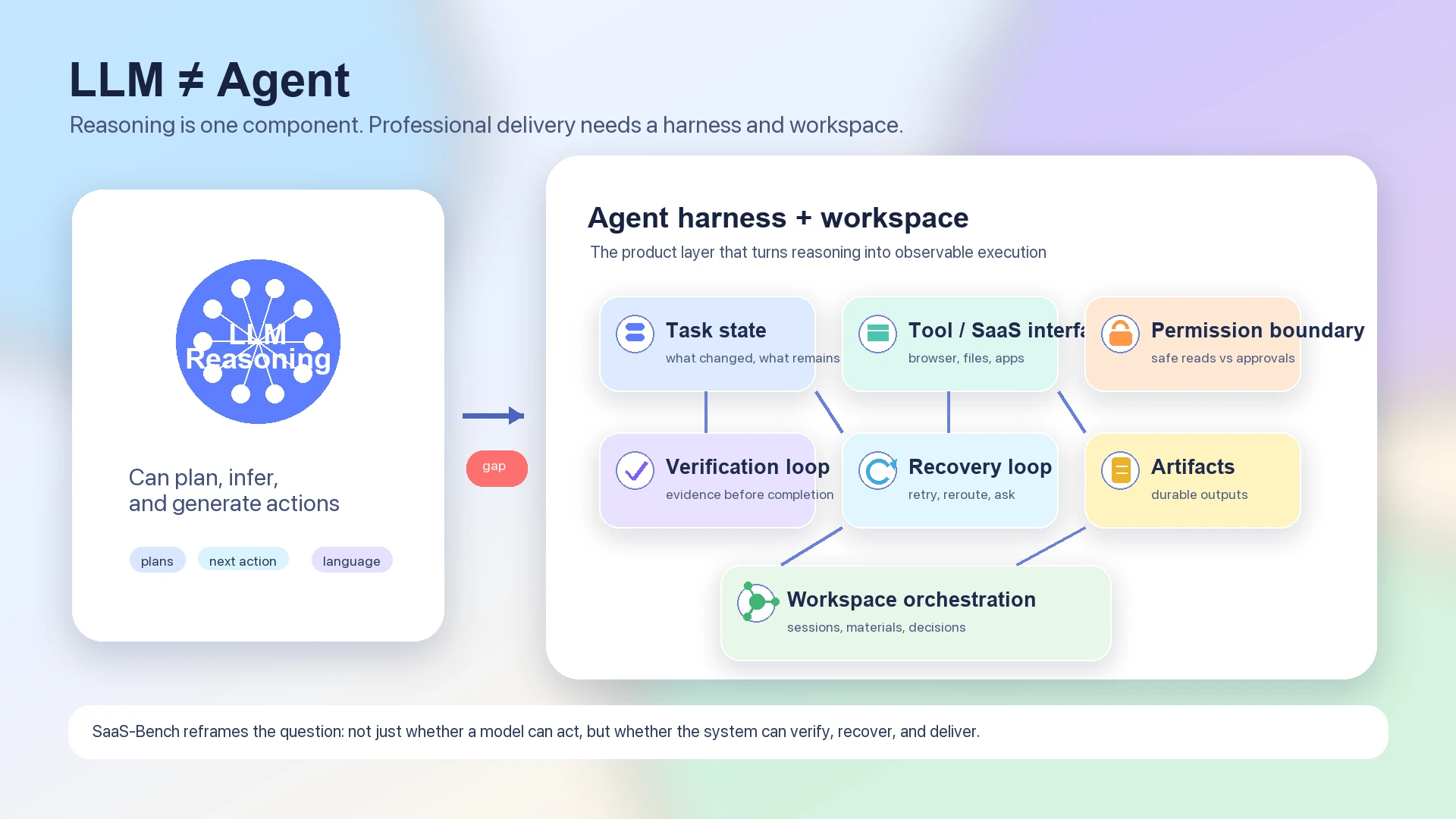 Un LLM est un composant dans une agent harness et une workspace architecture plus larges
Un LLM est un composant dans une agent harness et une workspace architecture plus larges
Un agent stack utile comporte donc au moins ces couches :
| Couche | Apport |
|---|---|
| LLM reasoning | Interprète les objectifs, rédige des plans, choisit les prochaines actions et explique les trade-offs. |
| Task state | Suit ce qui a été fait, ce qui reste ouvert et quelles hypothèses ne sont pas encore vérifiées. |
| Tool and SaaS interface | Connecte les actions navigateur, documents, fichiers, SaaS systems et outils externes en capabilities utilisables. |
| Permission boundary | Distingue les actions read-only sûres des actions nécessitant une approval ou une supervision explicite. |
| Verification loop | Vérifie que chaque state transition importante s'est réellement produite. |
| Recovery loop | Gère les failures, retries, partial completion, changements de UI state et résultats inattendus. |
| Artifact discipline | Produit des documents, records, tables, tickets, reports ou code changes durables plutôt que seulement des chat replies. |
| Workspace orchestration | Coordonne plusieurs sessions, materials, decisions et follow-up tasks dans le temps. |
Quand ces couches sont faibles, un modèle plus fort peut encore échouer. Il peut raisonner correctement dans l'abstrait, puis perdre le suivi du monde concret. Il peut accomplir la plupart des étapes visibles et manquer quand même la condition de vérification qui définit le succès. Il peut être capable de long reasoning mais manquer d'un mécanisme sûr pour le long-running work.
SaaS-Bench mesure indirectement ces couches manquantes. Le checkpoint score montre que les modèles peuvent contribuer. Le resolved score montre que cette contribution ne suffit pas.
L'échec n'est pas seulement une question d'« intelligence du modèle »
Il est tentant de lire les tables de benchmark comme une course entre modèles. C'est en partie vrai, mais incomplet.
Pour les tâches courtes, la qualité du modèle peut dominer. Si le travail est une réponse unique, le meilleur reasoning model gagne souvent. Pour les longs workflows SaaS, la distribution des échecs change. L'agent doit agir dans un monde stateful, permissioned, asynchronous et inconsistent. Le navigateur peut ne pas afficher l'élément attendu. Un document peut être enregistré au mauvais endroit. Un formulaire SaaS peut exiger une validation cachée. Une notification peut devoir référencer le bon artifact. Un workflow peut exiger de revenir à une app précédente après qu'une étape ultérieure a modifié le résultat requis.
Ce sont autant des harness problems que des reasoning problems.
Un modèle plus fort peut choisir de meilleures actions, mais il a toujours besoin d'un environnement capable de répondre à des questions opérationnelles :
- Quelle est la source of truth actuelle ?
- Qu'est-ce qui a changé après la dernière action ?
- Quel checkpoint dispose d'evidence, et quel checkpoint est seulement assumed ?
- Quelle step peut être retry en sécurité ?
- Quelle operation exige une user approval ?
- Quel artifact doit être transmis comme résultat final ?
- Quel failure doit déclencher recovery plutôt que continued execution ?
C'est la différence entre un chatbot qui peut décrire le travail et un agent system qui peut livrer le travail.
Un signal parallèle venu d'un autre SaaSBench
Il existe un autre benchmark au nom similaire, qu'il ne faut pas confondre avec SaaS-Bench. Le benchmark SaaSBench orienté coding est un benchmark différent, centré sur des tâches complexes de software engineering.3 Son setup rapporté comprend 30 complex tasks, 5,370 validation nodes, 8 languages, 6 databases et 13 frameworks, avec plus de 95% des failures se produisant avant que les agents n'atteignent la deep business logic.3
Les deux benchmarks sont différents, mais le signal parallèle est utile. Que l'environnement soit des opérations SaaS professionnelles ou du multi-service software engineering, de nombreux failures surviennent avant que le système n'atteigne le domain reasoning le plus profond. Les agents cassent sur l'échafaudage : setup, state, dependencies, interfaces, validation et recovery.
Cela ne rend pas le progrès des modèles sans importance. Cela change ce avec quoi le progrès des modèles doit être associé.
La couche produit devient l'Agent Harness
L'industrie des agents passe d'une course aux modèles à une course aux systèmes d'exécution.
Un bon harness n'est pas seulement une collection d'outils. C'est une couche produit au niveau du workspace qui rend l'agent work inspectable et governable. Elle doit aider l'utilisateur à comprendre ce que fait l'agent, ce qu'il a déjà fait, quelles preuves soutiennent l'achèvement et où le jugement humain est requis.
Pour des workflows de type SaaS-Bench, la harness layer a besoin de plusieurs propriétés.
State continuity. Les longs workflows exigent plus que du context stuffing. Le système doit connaître la différence entre une user instruction, une model hypothesis, un observed UI state, un saved artifact et une verified decision.
Checkpoint-aware execution. Si la tâche dépend d'une séquence d'outcomes, le workspace doit encourager la verification explicite. La progression partielle doit être visible, mais elle ne doit pas être confondue avec la completion.
Permission and action boundaries. Les workflows SaaS professionnels impliquent souvent records, invoices, medical administration, team documents ou external communication. Un agent system mature a besoin de approval points visibles et de defaults sûrs, surtout autour des actions irréversibles ou externally visible.
Recovery rather than collapse. Quand l'UI change ou qu'un tool échoue, le système ne doit pas simplement continuer à halluciner des progrès. Il doit détecter l'incertitude, préserver la failure evidence, retry en sécurité ou demander une decision à l'utilisateur.
Artifact-first output. Le produit final du travail professionnel est rarement une chat answer. C'est un report, un ticket, un spreadsheet, un submitted form, une document revision, un media asset ou un decision record. Un harness doit les traiter comme des durable objects.
Workspace orchestration. De nombreux workflows sont trop larges pour un thread monolithique. Research, execution, verification et final reporting peuvent être séparés en sessions ou workstreams, puis réconciliés par un workspace-level coordinator.
C'est pourquoi « agent harness » et « AI workspace » convergent. Le harness donne au modèle des mains, des guardrails, une memory et de l'inspection. Le workspace donne à l'utilisateur un lieu pour superviser, organiser et poursuivre le travail.
Où se situe MCPlato
SaaS-Bench ne doit pas être lu comme l'affirmation qu'un workspace particulier a résolu le travail SaaS autonome. MCPlato n'a pas affirmé publiquement exécuter SaaS-Bench ni éliminer les failure modes du benchmark. La conclusion responsable est plus étroite et plus pratique : le benchmark valide pourquoi la workspace architecture compte.
MCPlato est conçu autour de l'idée que le travail sérieux d'agent exige plus qu'un unique chat transcript. À haut niveau, il donne aux utilisateurs une manière d'organiser agent execution grâce à des workspaces, sessions, connected materials, visible artifacts et supervised continuation.
Plusieurs concepts de MCPlato correspondent naturellement à la leçon de SaaS-Bench :
- Multi-session orchestration. Le long travail professionnel se décompose souvent en research, execution, review et synthesis. Des sessions séparées aident à préserver les frontières tout en permettant à l'utilisateur de coordonner l'objectif global.
- Sprite / virtual partner. Un workspace-level partner peut aider à suivre ce qui est active, blocked, complete et ce qui demande encore review. La valeur est l'orchestration, pas la mise en scène.
- Artifact discipline. Les outputs doivent devenir des deliverables inspectables : documents, reports, plans, diagrams, code changes ou autres files qui peuvent être revus hors du chat flow.
- Local-first connected materials. Le travail réel dépend de local documents, project folders, notes et source materials. Un workspace qui garde ces materials proches de la task peut réduire le context loss.
- Scheduled and background tasks. Certains agent work bénéficient d'une continuation hors d'un unique chat turn synchrone, surtout lorsqu'il implique research, checking ou batch production.
- Permissioned and observable execution. Les utilisateurs doivent pouvoir voir quelles actions ont été tentées et décider quand une step nécessite approval, surtout quand l'agent touche des external systems ou des durable artifacts.
- Decision trace. Les longs workflows ont besoin d'une mémoire de ce qui a été accepted, rejected, deferred et pourquoi. Sans cette trace, une étape ultérieure de l'agent peut annuler par accident la rationale d'une étape précédente.
La formulation importante est « aide à organiser et superviser ». Un workspace harness ne rend pas chaque agent autonomous, correct ou safe par défaut. Il donne à l'utilisateur et à l'agent une meilleure execution surface : une surface où state, artifacts, permissions et recovery font partie de l'expérience produit plutôt que d'être cachés dans un transcript.
Ce que SaaS-Bench suggère sur la prochaine vague d'Agents
Le benchmark pointe vers une définition plus réaliste de l'agent progress.
Le prochain agent system utile ne sera pas jugé seulement sur la fluidité de son raisonnement textuel. Il sera jugé sur sa capacité à maintenir continuity entre applications, préserver evidence, récupérer après des partial failures, demander permission au bon moment et produire des artifacts auxquels un professionnel peut faire confiance.
C'est une barre plus haute que « le modèle peut appeler des tools ». Tool use n'est que l'interface. La question produit est de savoir si le harness environnant peut rendre tool use fiable sur de longs workflows.
SaaS-Bench donne à l'industrie un vocabulaire plus précis pour cet écart :
- checkpoint progress n'est pas la même chose que resolved completion ;
- browser control n'est pas la même chose que professional workflow delivery ;
- model reasoning n'est pas la même chose qu'agent execution ;
- un chat transcript n'est pas la même chose qu'un workspace ;
- autonomy sans observability n'est pas une product strategy.
La conclusion n'est pas que les modèles plus grands ne comptent pas. Ils comptent. Mais à mesure que les modèles s'améliorent, les failures restants deviennent de plus en plus architectural. La frontière compétitive se déplace vers harnesses, workspaces, verification loops, permission models et artifact systems.
La course aux modèles continue. SaaS-Bench suggère que la prochaine course est celle des execution systems.
References
Footnotes
-
SaaS-Bench arXiv paper et SaaS-Bench HTML version, incluant le title, les authors, task composition, multi-application statistics, workflow-step statistics, scoring definitions et Table 2 benchmark scores cités dans cet article. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
Official SaaS-Bench benchmark page and live leaderboard, incluant les official live leaderboard scores et les 3,971 weighted checkpoints indiqués. ↩ ↩2 ↩3 ↩4
-
SaaSBench coding benchmark arXiv paper. Il s'agit d'un benchmark différent de SaaS-Bench ; il est cité uniquement comme signal de comparaison en arrière-plan. ↩ ↩2