So nutzen Sie allgemeine AI Agents, ohne die Kontrolle zu verlieren
Allgemeine AI Agents sind am nützlichsten, wenn sie in begrenzten, prüfbaren Workflows laufen. Dieser Leitfaden behandelt Prompt-Verträge, Strukturen für lang laufende Aufgaben, menschliche Checkpoints, kuratierte Umgebungen und überprüfbare Artefakte für Agents wie Hermes, OpenClaw-nahe Gateways und MCPlato.
Die meisten Menschen verlieren die Kontrolle über einen allgemeinen AI Agent nicht, weil der Prompt zu kurz ist. Sie verlieren sie, weil die Arbeit nie in einen kontrollierbaren Workflow geformt wurde.
Ein allgemeiner Agent ist nicht nur ein Coding-Assistent. Er kann recherchieren, einen Browser bedienen, Dokumente zusammenfassen, Arbeit planen, Teilaufgaben koordinieren, Artefakte vorbereiten oder in einem Workspace handeln. Tools wie Hermes, OpenClaw-nahe Gateways und MCPlato weisen auf dieses breitere Muster hin: ein AI Partner, der Tools und Kontext über längere Zeit nutzen kann. Die öffentliche Dokumentation von OpenClaw ist weiterhin stark auf Coding-Agent-Workflows ausgerichtet. Daher sollte OpenClaw hier eher als Beispiel für Grenzen und Gateways verstanden werden, nicht als vollständiges Playbook für allgemeine Agents.
Die praktische Frage lautet deshalb nicht: "Wie schreibe ich einen schöneren Prompt?" Sie lautet: Wie entwerfe ich begrenzte, prüfbare Arbeit, damit ein Agent helfen kann, ohne stillschweigend die Kontrolle zu übernehmen?
Die folgenden fünf Praktiken machen allgemeine Agents zuverlässiger für Wissensarbeit, Operations, Recherche und mehrstufige Ausführung.
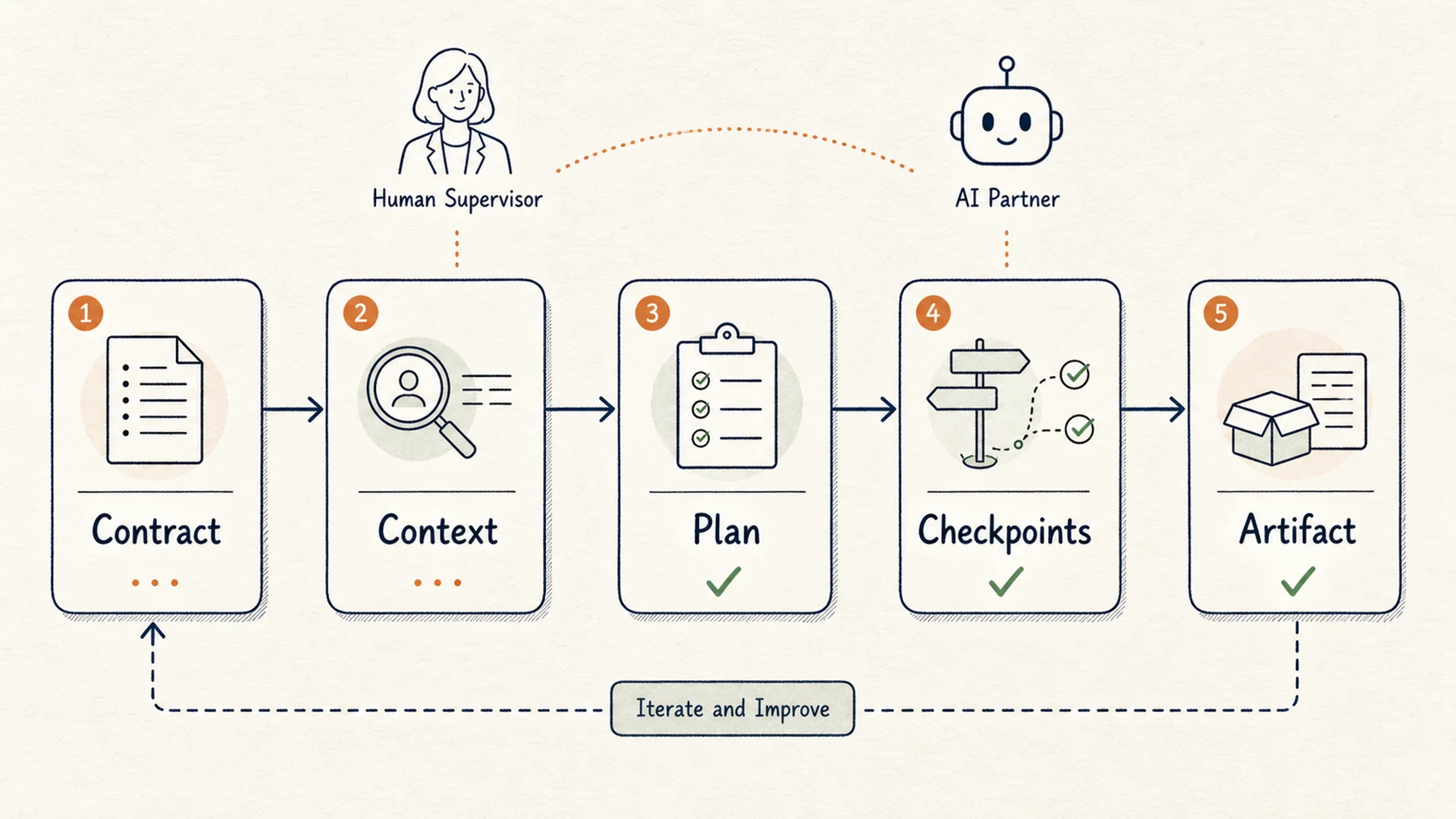 Diagramm eines begrenzten Workflows zur Nutzung allgemeiner AI Agents
Diagramm eines begrenzten Workflows zur Nutzung allgemeiner AI Agents
1. Schreiben Sie einen Prompt-Vertrag, keinen Wunsch
Eine schwache Anweisung klingt so:
Recherchiere dieses Thema und erstelle einen guten Bericht.
Eine stärkere Anweisung verhält sich wie ein operativer Vertrag. Sie sagt dem Agent, was Erfolg bedeutet, wo die Grenzen liegen, welche Belege erforderlich sind und wann der Agent stoppen muss.
Ein nützlicher Prompt für allgemeine Agents sollte meist Folgendes enthalten:
| Vertragsfeld | Was angegeben werden sollte |
|---|---|
| Ziel | Das Ergebnis, das der Nutzer wirklich braucht, nicht nur die Aktivität. |
| Erfolgskriterien | Was wahr sein muss, damit die Aufgabe als abgeschlossen gilt. |
| Fehlerbedingungen | Wann gestoppt, eskaliert oder Unsicherheit gemeldet werden soll. |
| Eingangsmaterialien | Welche Dateien, Links, Notizen, Datensätze oder früheren Entscheidungen verbindlich sind. |
| Tools und verbotene Tools | Was der Agent nutzen darf und was er nicht nutzen darf. |
| Bestätigungspflichtige Aktionen | Welche Aktionen vor der Ausführung eine Freigabe benötigen. |
| Checkpoints | Wo der Agent pausieren und den Fortschritt zusammenfassen soll. |
| Endartefakt | Das erwartete Ergebnis: Memo, Tabelle, Deck, Ticket, Plan, Spreadsheet, Bild oder Entscheidungsprotokoll. |
| Belege | Zitate, Logs, Screenshots, Testergebnisse, Dateipfade oder Annahmen, die das Ergebnis stützen. |
Dieses Framing passt zu den Prompt-Empfehlungen von AWS, die klare Ziele, Aufgabenbeschränkungen und erwartete Ausgaben betonen. Es passt auch zu den Empfehlungen von Anthropic zum Aufbau effektiver Agents, nach denen Agents am besten funktionieren, wenn Workflows bewusst zusammengesetzt werden, statt sie vager Autonomie zu überlassen.
Der Punkt ist nicht, jeden Prompt lang zu machen. Der Punkt ist, den operativen Vertrag explizit zu machen. Kurze Prompts sind für kurze Aufgaben in Ordnung. Lang laufende, toolnutzende Agents brauchen Verträge.
2. Teilen Sie lange Arbeit in Pläne, Checkpoints und Wiederherstellungszustände auf
Allgemeine Agents werden fragil, wenn sie eine lange Aufgabe als einen einzigen ununterbrochenen Gedankenfaden tragen sollen. Lang laufende Arbeit sollte als Abfolge prüfbarer Zustände strukturiert werden:
- Plan: Was getan wird, in welcher Reihenfolge und warum.
- Teilaufgaben: Arbeitseinheiten, die klein genug sind, um überprüft zu werden.
- Checkpoints: Stellen, an denen Nutzer oder System den Fortschritt prüfen können.
- Wiederherstellung: Eine Möglichkeit, nach einer Unterbrechung fortzusetzen, erneut zu versuchen oder zurückzurollen.
- Abschließende Synthese: Ein dauerhaftes Artefakt, das zusammenfasst, was sich geändert hat und was offen bleibt.
Das orchestrator-workers-Muster von Anthropic ist hier nützlich: Ein koordinierender Agent zerlegt die Aufgabe, während spezialisierte worker begrenzte Teilaufgaben bearbeiten. Die Persistenz- und Interrupt-Muster von LangGraph zeigen dieselbe architektonische Idee aus einem anderen Blickwinkel: Lang laufende Agents brauchen Zustand, Checkpoints und die Möglichkeit, vor sensiblen Aktionen zu pausieren.
Hermes zeigt ebenfalls, warum Umgebungen für allgemeine Agents dauerhaften Speicher, geplante Automatisierungen, isolierte Subagents und Tool-Grenzen benötigen. Das sind keine kosmetischen Funktionen. Sie ermöglichen es einem Agent, Arbeit zu überstehen, die viele Schritte, mehrere Sitzungen oder Hintergrundausführung umfasst.
In MCPlato erscheint dasselbe Prinzip als Koordination auf Workspace-Ebene: Mehrere Sitzungen können unterschiedliche Teile der Arbeit halten, ein virtueller Partner oder Sprite kann den Fortschritt koordinieren, verbundene Materialien können local-first bleiben, und geplante oder Hintergrundaufgaben können weiterlaufen, ohne alles in ein einziges Chatprotokoll zu pressen. Das macht MCPlato nicht zu einem magischen Ersatz für Prozessdesign. Es macht das Prozessdesign lediglich leichter bewahrbar.
3. Setzen Sie menschliche Prüfung an Risikogrenzen, nicht bei jedem Klick
Human-in-the-loop-Kontrolle wird oft missverstanden. Wenn ein Nutzer jeden winzigen Schritt freigeben muss, wird der Agent langsamer als manuelle Arbeit. Wenn der Agent alles ohne Prüfung tun kann, hat der Nutzer keine echte Kontrolle.
Das bessere Muster ist eine Risikoleiter.
 Risikoleiter, die zeigt, wo menschliche Bestätigung erfolgen sollte
Risikoleiter, die zeigt, wo menschliche Bestätigung erfolgen sollte
Aktionen mit geringem Risiko können meist mit leichter Aufsicht laufen:
- bereitgestellte Materialien lesen;
- innerhalb eines genehmigten Workspace suchen;
- eine Gliederung entwerfen;
- Quellen zusammenfassen;
- nächste Schritte vorschlagen.
Aktionen mit mittlerem Risiko sollten einen Checkpoint erzeugen:
- ein Dokument ändern;
- einen kundenorientierten Entwurf erstellen;
- eine Aufgabenliste anlegen;
- eine Datentransformation vorbereiten;
- eine Entscheidung empfehlen.
Aktionen mit hohem Risiko sollten explizite Bestätigung erfordern:
- eine Nachricht extern senden;
- Daten löschen oder überschreiben;
- kaufen, veröffentlichen, deployen oder einreichen;
- auf sensible Systeme zugreifen;
- schwer rückgängig zu machende Aktionen ausführen.
Das entspricht der Richtung von Anthropics Arbeit zu vertrauenswürdigen Agents und Computer Use, den Human-in-the-loop-Kontrollen des OpenAI Agents SDK und Microsofts Responsible-AI-Leitlinien: Aufsicht sollte an Risiko, Autorität, Umkehrbarkeit und Wirkung gebunden sein.
Eine gute Anweisung lautet daher nicht: "Frag mich, bevor du irgendetwas tust." Sie ist spezifischer:
Du darfst alle bereitgestellten Materialien lesen und zusammenfassen. Du darfst Dateien entwerfen. Bevor du Nachrichten sendest, Dateien löschst, Berechtigungen änderst, veröffentlichst oder irreversible Änderungen vornimmst, stoppe und bitte mit einer kurzen Erklärung des Risikos um Bestätigung.
Diese Art Grenze hält den Agent nützlich und bewahrt zugleich die menschliche Autorität.
4. Kuratieren Sie die Umgebung des Agent, bevor Sie die Autonomie erhöhen
Wenn ein allgemeiner Agent schlecht arbeitet, versuchen Nutzer oft, es mit mehr Anweisungen zu beheben. Manchmal ist das eigentliche Problem die Umgebung.
Agents brauchen eine kuratierte Arbeitsoberfläche:
- Verbindliche Materialien: Sagen Sie dem Agent, welche Dateien, Links, Notizen oder Repositories am wichtigsten sind.
- Minimal notwendige Berechtigungen: Lesezugriff vor Schreibzugriff; lokaler Zugriff vor externem Zugriff; reversible Aktionen vor irreversiblen Aktionen.
- Sichere Ausführungszonen: Nutzen Sie Sandboxes, Entwürfe, Staging-Umgebungen oder isolierte Workspaces für riskante Arbeit.
- Klare Netzwerkgrenzen: Definieren Sie, welche Quellen erlaubt, blockiert oder bevorzugt sind.
- Tool-Ausgaben mit hohem Signalwert: Tools sollten strukturierte, knappe, handlungsfähige Ergebnisse liefern statt verrauschter Dumps.
- Persistenter Kontext: Wichtige Entscheidungen, Annahmen und Artefakte sollten einen Chat-Turn überdauern.
Die Leitlinien von Anthropic zu Computer Use und Tool Writing weisen immer wieder auf dieselbe Idee hin: Die Qualität eines Agent hängt stark von den Tools und der Umgebung um ihn herum ab. AWS beschreibt Computer-Use-Agents ebenfalls als Systeme, die Aufgabenausführung, Tools und Sicherheitsbeschränkungen verwalten müssen, nicht nur Prompts.
Für allgemeine Agents ist das noch wichtiger als für enge Coding-Agents. Ein Coding-Assistent lebt oft in einem Repository mit Tests, Diffs und Versionskontrolle. Ein allgemeiner Agent kann über Dokumente, Kalender, Browser-Tabs, Nachrichten, PDFs, Notizen und interne Richtlinien hinweg arbeiten. Ohne kuratierte Umgebung muss der Agent raten, was wichtig ist.
Die local-first verbundenen Materialien von MCPlato sind eine Möglichkeit, dies handhabbar zu machen: Der Nutzer kann das relevante Verzeichnis, Dateien oder Projektkontext anhängen und Agent-Sitzungen dann innerhalb dieser kuratierten Grenze arbeiten lassen. Das wichtige Prinzip ist übertragbar: Bitten Sie einen Agent nicht, in einer Umgebung autonom zu sein, die Sie nicht vorbereitet haben.
5. Verlangen Sie überprüfbare Artefakte, nicht nur Chat-Antworten
Das Endergebnis von Agent-Arbeit sollte meist etwas sein, das der Nutzer prüfen kann, ohne die gesamte Unterhaltung erneut abzuspielen.
Zum Beispiel:
| Aufgabentyp | Schwache Ausgabe | Besseres Artefakt |
|---|---|---|
| Recherche | "Das habe ich gefunden." | Ein belegtes Briefing mit Aussagen, Zitaten und offenen Fragen. |
| Operations | "Ich habe die Aufgabe erledigt." | Eine Checkliste mit ausgeführten Aktionen, geänderten Dateien und ungelösten Punkten. |
| Planung | "Hier ist ein Plan." | Ein Meilensteinplan mit Verantwortlichen, Abhängigkeiten, Risiken und Entscheidungspunkten. |
| Content | "Hier ist ein Entwurf." | Ein Dokument mit Struktur, Referenzen, Bildern und Revisionsnotizen. |
| Datenarbeit | "Die Daten sind bereinigt." | Ein Spreadsheet oder eine Tabelle plus Transformationsnotizen und Validierungsprüfungen. |
Artifact-first-Arbeit wird zu einem verbreiteten Produktmuster. Claude Artifacts machte dauerhafte Ausgaben für Nutzer sichtbarer. OpenAI tracing und LangSmith observability zeigen den angrenzenden operativen Bedarf: Wenn Agents handeln, brauchen Teams Spuren, Belege und prüfbaren Zustand. Microsofts Responsible-AI-Leitlinien betonen ebenfalls Verantwortlichkeit, Monitoring, Governance und menschliche Aufsicht.
Für einen allgemeinen Agent ist das Artefakt keine Dekoration. Es ist die Kontrollfläche. Es lässt den Nutzer fragen:
- Was hat der Agent tatsächlich erzeugt?
- Welche Quellen oder Tools haben es gestützt?
- Welche Entscheidungen wurden getroffen?
- Welche Aktionen sind noch offen?
- Was sollte ein Mensch vor dem nächsten Schritt prüfen?
MCPlatos Artefaktdisziplin und Entscheidungsspuren passen natürlich zu diesem Muster: Der Wert liegt nicht nur darin, dass ein AI Partner bei der Arbeit helfen kann, sondern darin, dass die Arbeit über Sitzungen hinweg sichtbar, wiederaufnehmbar und überprüfbar werden kann.
Eine praktische Startvorlage
Wenn Sie einen wiederverwendbaren Prompt für einen allgemeinen Agent möchten, beginnen Sie damit:
Ziel:
[Beschreiben Sie das echte Ergebnis, nicht nur die Aktivität.]
Kontext und Materialien:
[Hängen Sie verbindliche Dateien, Links, Notizen und Beschränkungen an oder listen Sie sie auf.]
Erfolgskriterien:
[Definieren Sie, was am Ende wahr sein muss.]
Grenzen:
[Erlaubte Tools, verbotene Tools, Datenlimits, Netzwerklimits und Berechtigungsregeln.]
Workflow:
1. Ziel und Annahmen neu formulieren.
2. Einen kurzen Plan vorschlagen.
3. In kleinen Teilaufgaben ausführen.
4. An den folgenden Checkpoints pausieren: [Checkpoints auflisten].
5. Vor Folgendem um Bestätigung bitten: [Aktionen mit hohem Risiko].
Belege:
[Zitate, Logs, Screenshots, Dateipfade, Diffs oder Validierungsnotizen verlangen.]
Endartefakt:
[Lieferformat und Ort zum Speichern oder Anzeigen angeben.]
Wenn blockiert:
[Blocker, unternommene Versuche und sicherste nächste Option melden.]
Diese Vorlage ist absichtlich einfach. Sie funktioniert, weil sie Agent-Nutzung von offener Delegation in begrenzte Zusammenarbeit verwandelt.
Fazit: Kontrolle ist eine Workflow-Eigenschaft
Allgemeine Agents werden nicht allein durch Prompts zuverlässig. Sie brauchen klare Verträge, kuratierten Kontext, Berechtigungsgrenzen, Checkpoints, Wiederherstellungspfade und dauerhafte Artefakte.
Das gilt, ob der Agent Hermes-artige Automatisierung, ein OpenClaw-nahes Gateway, MCPlatos Multi-Session-AI-Partner-Modell oder eine andere allgemeine Agent-Umgebung ist. Das Erfolgsmodell ist nicht maximale Autonomie. Es ist begrenzte Autonomie mit Prüfung.
Wenn Nutzer den Workflow entwerfen, können Agents mit mehr Vertrauen handeln. Wenn Nutzer den Workflow überspringen, wird selbst ein fähiger Agent zu einer sehr schnellen Quelle von Unsicherheit.
Referenzen
- AWS Prescriptive Guidance: Computer use agents
- AWS Connect: Best Practices fuer Prompts im agentischen Self-Service
- Anthropic: Effektive Agents bauen
- LangGraph Persistenz
- LangGraph Interrupts
- Hermes Dokumentation
- Anthropic: Auf dem Weg zu vertrauenswuerdigen AI Agents
- Claude Computer-Use-Tool-Dokumentation
- OpenAI Agents SDK: Human in the Loop
- Microsoft: Responsible AI fuer Agents in der gesamten Organisation
- Anthropic Engineering: Tools fuer Agents schreiben
- OpenClaw Dokumentation
- Claude Artifacts
- OpenAI Agents SDK: Tracing
- LangSmith Observability
- MCPlato