Warum SaaS-Bench zeigt, dass AI Agents Harnesses brauchen, nicht nur größere Modelle
SaaS-Bench testet computer-use agents in realen professionellen SaaS-Workflows und legt die Lücke zwischen Teilfortschritt und verifizierter Fertigstellung offen. Das Ergebnis verweist auf agent harnesses, workspace state, verification, permissions und recovery als nächste Produktschicht.
Veröffentlicht am 2026-05-25
Weniger als vier Prozent ist die unbequeme Schlagzeile.
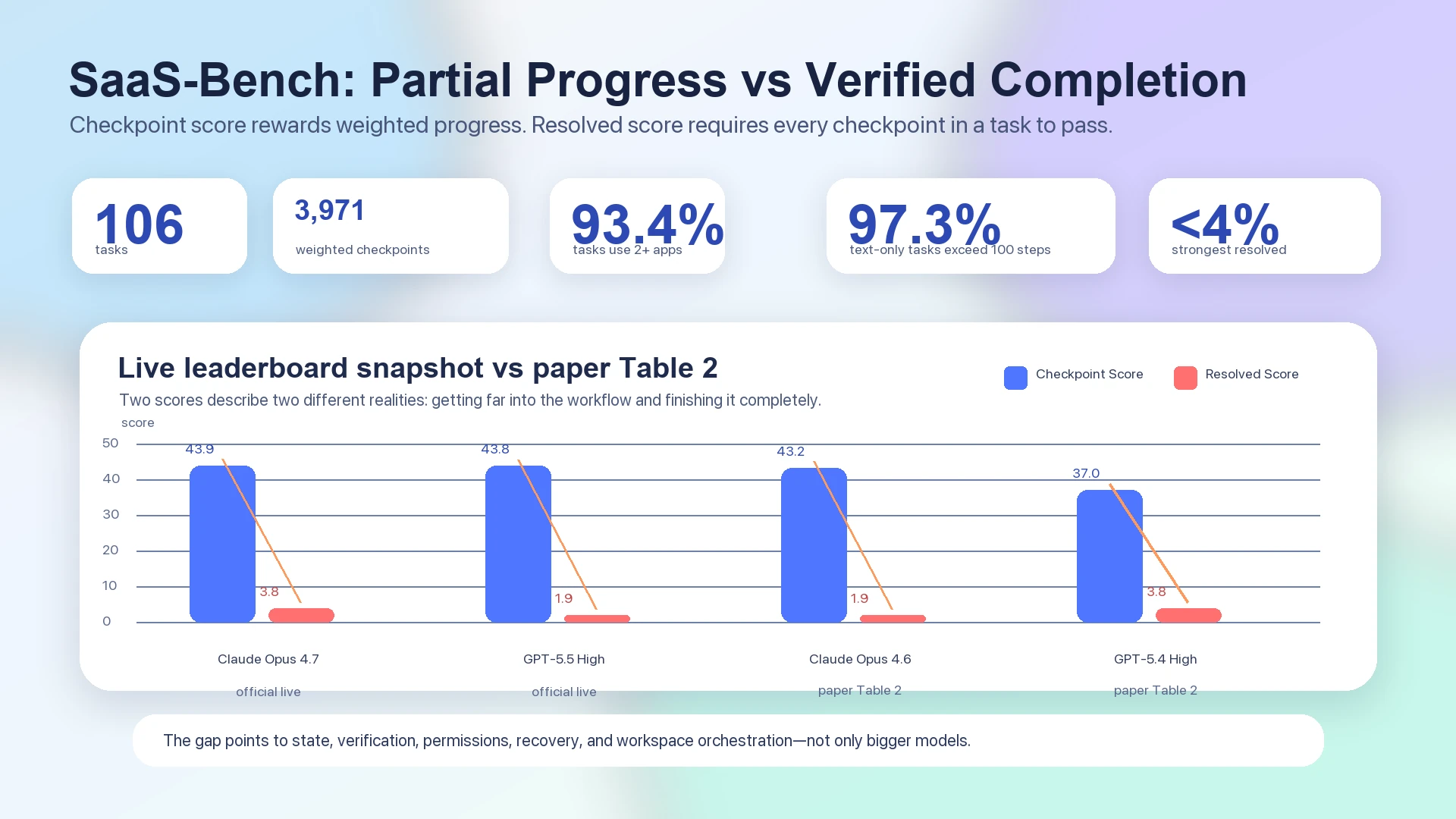
Im SaaS-Bench-Paper bleibt der stärkste end-to-end Resolved Score unter vier Prozent: Claude Opus 4.6 wird in Table 2 mit 43.2 overall checkpoint score und 1.9 resolved score ausgewiesen, während GPT-5.4 High mit 37.0 overall checkpoint score und 3.8 resolved score ausgewiesen wird.1 Das offizielle Live-Leaderboard, das getrennt von der statischen Tabelle im Paper betrachtet werden sollte, zeigt ebenfalls Spitzensysteme, deren checkpoint score im niedrigen Vierzig-Bereich liegt, während der resolved score weiterhin bei 3.8 oder 1.9 landet: Claude Opus 4.7 bei 43.9 checkpoint / 3.8 resolved und GPT-5.5 High bei 43.8 checkpoint / 1.9 resolved.2
Diese Lücke ist die eigentliche Geschichte. Computer-use agents können in langen SaaS-Workflows sichtbaren Fortschritt erzielen, aber sie bringen den Workflow selten bis zur verifizierten Fertigstellung. Der Engpass ist nicht nur Modellintelligenz. Es ist das fehlende Ausführungssystem um das Modell herum: state, verification, permissions, recovery, artifacts und workspace orchestration.
SaaS-Bench ist daher nicht deshalb nützlich, weil es erklärt, dass agents schwach sind, sondern weil es klärt, welche Art von Produktschicht agents jetzt brauchen.
Was SaaS-Bench misst
SaaS-Bench trägt den Titel “SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows?” Verfasst wurde es von Kean Shi, Zihang Li, Tianyi Ma, Zengji Tu, Jialong Wu, Xinbo Xu, Qingyao Yang, Ruoyu Wu, Weichu Xie, Ming Wu, Jason Zeng, Michael Heinrich, Elvis Zhang, Liang Chen, Kuan Li und Baobao Chang.1
Der benchmark bewertet agents auf 23 deploybaren open-source SaaS-Systemen, über 6 professionelle Domänen und 106 Aufgaben hinweg.1 Diese Domänen sind Software Engineering & Project Management, Business Operations & Finance, Healthcare Administration, Team Collaboration & Document Workflow, Artisan Agri-Food Supply Chain und Independent Media Creation.1
Das ist wichtig. Der benchmark ist kein schmales Browser-Klick-Spielzeug. Er liegt näher an der operativen Arbeit, die Fachkräfte leisten, wenn sie zwischen Dokumenten, Projektboards, Dashboards, Formularen, Kalendern, Finanzsystemen und Medientools wechseln.
Die Aufgabenverteilung macht das konkret. SaaS-Bench enthält 74 text-only tasks und 32 multimodal tasks.1 Außerdem betont es cross-application work: 99 von 106 Aufgaben, also 93.4%, beziehen mindestens 2 Anwendungen ein, während 53 Aufgaben, also 50.0%, 3 Anwendungen einbeziehen.1 Die Workflows sind ebenfalls lang: 72 von 74 text-only tasks, also 97.3%, überschreiten 100 Schritte, und 19 von 32 multimodal tasks, also 61.3%, überschreiten 100 Schritte.1
Die offizielle benchmark-Seite sagt, die Suite enthalte 3,971 weighted verification checkpoints.2 Das scoring design ist entscheidend: Checkpoint Score misst gewichteten Teilfortschritt, während Resolved Score verlangt, dass alle checkpoints einer Aufgabe bestehen.2 Anders gesagt fragt der benchmark nicht nur: "Sah der agent beschäftigt aus?" Er fragt: "Endete der professionelle Workflow tatsächlich in einem verifizierten Zustand?"
Die Checkpoint / Resolved-Lücke ist das Kernsignal
Das aufschlussreichste Ergebnis von SaaS-Bench ist nicht, dass agents null Punkte erzielen. Das tun sie nicht. Die stärkeren Systeme sammeln bedeutsames checkpoint credit. Sie können navigieren, lesen, eingeben, suchen, zusammenfassen und sich manchmal weit genug erholen, um viele Zwischenbedingungen zu erfüllen.
Das Problem ist, dass professionelle Workflows multiplikativ sind. Wenn eine Aufgabe viele abhängige Schritte hat, können wenige kleine Defekte das Endergebnis unbrauchbar machen. Ein fehlender permission step, fortgeschleppter veralteter state, ein falsch aktualisierter SaaS record, eine nicht validierte hochgeladene artifact oder eine verlorene cross-app dependency können den Workflow unresolved lassen, selbst nach sichtbarem Fortschritt.
 Ein Datenbruchdiagramm zeigt die SaaS-Bench-Luecke zwischen checkpoint progress und verified completion
Ein Datenbruchdiagramm zeigt die SaaS-Bench-Luecke zwischen checkpoint progress und verified completion
Abbildung: SaaS-Bench-Daten trennen Teilfortschritt von verifizierter Fertigstellung. Table 2 des Papers und das offizielle Live-Leaderboard zeigen beide deutlich höhere checkpoint scores als resolved scores.12
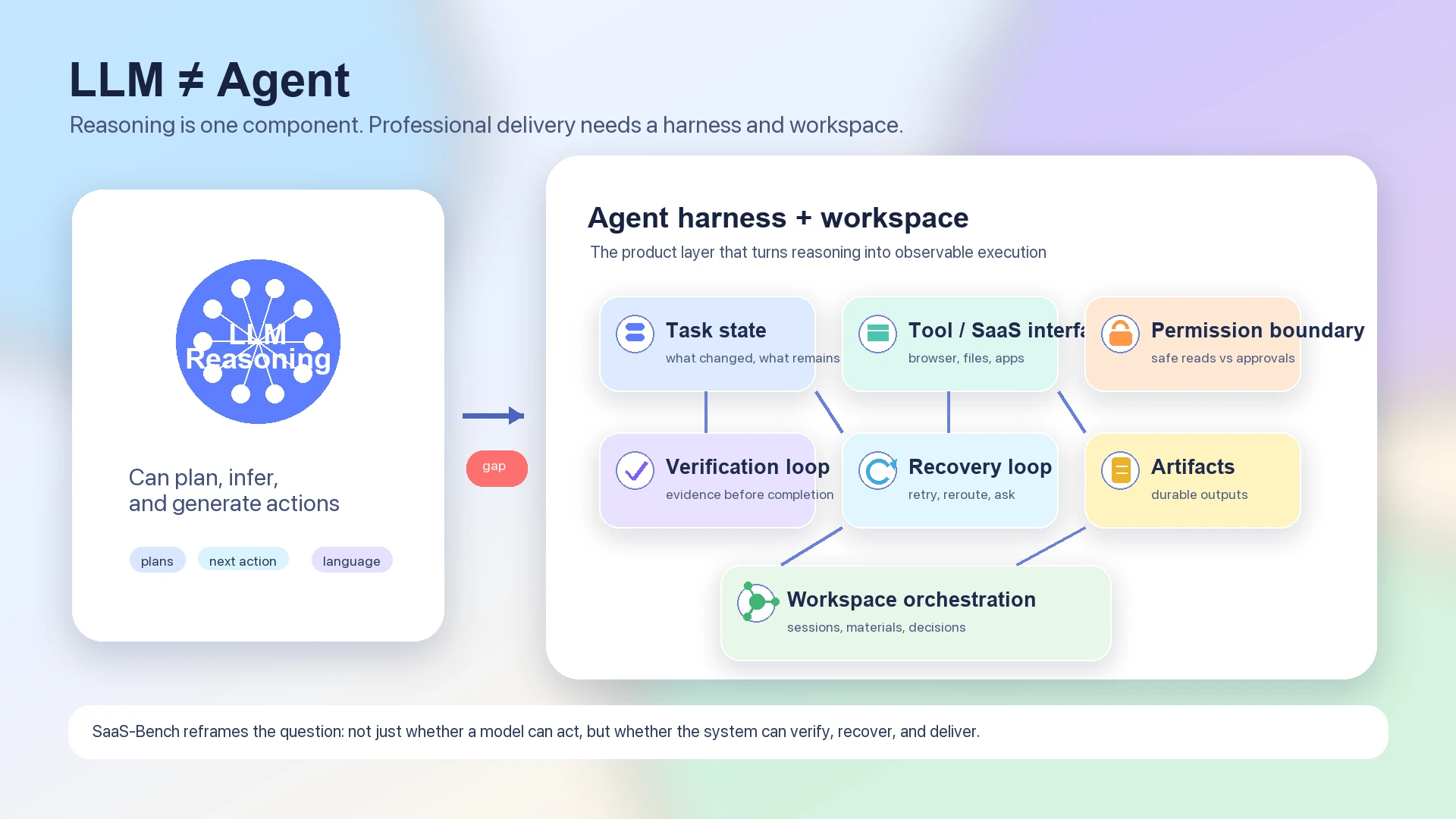
Darum passt der benchmark besser zur Diskussion über agent architecture als zu einfachem Modellranking. Ein reines LLM kann planen, schließen und nächste actions generieren. Aber ein funktionierender agent muss auch state über viele Schritte hinweg bewahren, prüfen, ob sich die Welt wie erwartet geändert hat, wissen, wann permission einzuholen ist, sicher retry ausführen und artifacts hinterlassen, die geprüft werden können.
Das Modell ist die Reasoning-Engine. Der harness ist das Ausführungssystem.
LLM ist nicht gleich Agent
Der Ausdruck "AI agent" verdichtet oft mehrere Schichten zu einem einzigen Wort. SaaS-Bench macht diese Verdichtung schwerer zu verteidigen.
Ein Sprachmodell kann einen Plan erzeugen wie: "Öffne das CRM, aktualisiere den Kundendatensatz, hänge das unterschriebene Dokument an, benachrichtige das Team und gleiche die Rechnung ab." Der professionelle Workflow verlangt aber mehr als einen Plan. Das System muss wissen, welcher browser state aktuell ist, welche SaaS app maßgeblich ist, welche Datei das artifact of record ist, welche action reversibel ist, welche action user approval braucht und welcher checkpoint beweist, dass die Aufgabe abgeschlossen ist.
 Ein LLM ist eine Komponente innerhalb einer groesseren agent harness und workspace architecture
Ein LLM ist eine Komponente innerhalb einer groesseren agent harness und workspace architecture
Ein nützlicher agent stack hat daher mindestens diese Schichten:
| Schicht | Beitrag |
|---|---|
| LLM reasoning | Interpretiert Ziele, entwirft Pläne, wählt nächste actions und erklärt trade-offs. |
| Task state | Verfolgt, was erledigt wurde, was offen bleibt und welche Annahmen noch unverifiziert sind. |
| Tool and SaaS interface | Verbindet Browseraktionen, Dokumente, Dateien, SaaS systems und externe Tools zu nutzbaren capabilities. |
| Permission boundary | Unterscheidet sichere read-only actions von actions, die ausdrückliche approval oder supervision erfordern. |
| Verification loop | Prüft, ob jede wichtige state transition tatsächlich stattgefunden hat. |
| Recovery loop | Behandelt Fehler, retries, partial completion, geänderten UI state und unerwartete Ergebnisse. |
| Artifact discipline | Erzeugt dauerhafte documents, records, tables, tickets, reports oder code changes statt nur chat replies. |
| Workspace orchestration | Koordiniert mehrere sessions, materials, decisions und follow-up tasks über die Zeit. |
Wenn diese Schichten schwach sind, kann auch ein stärkeres Modell scheitern. Es kann abstrakt korrekt reasoning betreiben und dann den konkreten Zustand der Welt verlieren. Es kann die meisten sichtbaren Schritte abschließen und trotzdem die eine verification condition verpassen, die Erfolg definiert. Es kann zu langem reasoning fähig sein, aber keinen sicheren mechanism für long-running work haben.
SaaS-Bench misst diese fehlenden Schichten indirekt. Der checkpoint score zeigt, dass Modelle beitragen können. Der resolved score zeigt, dass dieser Beitrag nicht ausreicht.
Scheitern ist nicht nur "Modellintelligenz"
Es ist verlockend, benchmark-Tabellen als Modellrennen zu lesen. Das ist teilweise richtig, aber unvollständig.
Bei kurzen Aufgaben kann Modellqualität dominieren. Wenn die Arbeit eine einzelne Antwort ist, gewinnt oft das stärkste reasoning model. Bei langen SaaS-Workflows verschiebt sich die Fehlerverteilung. Der agent muss in einer Welt handeln, die stateful, permissioned, asynchronous und inconsistent ist. Der Browser zeigt vielleicht nicht das erwartete Element. Ein Dokument wird vielleicht am falschen Ort gespeichert. Ein SaaS-Formular verlangt vielleicht eine versteckte validation. Eine Benachrichtigung muss möglicherweise das richtige artifact referenzieren. Ein Workflow kann erfordern, zu einer früheren app zurückzugehen, nachdem ein späterer Schritt die erforderliche Ausgabe verändert hat.
Das sind harness problems genauso wie reasoning problems.
Ein stärkeres Modell kann bessere actions wählen, braucht aber weiterhin eine Umgebung, die operative Fragen beantworten kann:
- Was ist die aktuelle source of truth?
- Was hat sich nach der letzten action geändert?
- Welcher checkpoint hat evidence, und welcher checkpoint ist nur assumed?
- Welcher step lässt sich sicher retry ausführen?
- Welche operation erfordert user approval?
- Welches artifact sollte als Endergebnis übergeben werden?
- Welcher failure sollte recovery statt continued execution auslösen?
Das ist der Unterschied zwischen einem chatbot, der Arbeit beschreiben kann, und einem agent system, das Arbeit liefern kann.
Ein paralleles Signal von einem anderen SaaSBench
Es gibt einen weiteren benchmark mit ähnlichem Namen, der nicht mit SaaS-Bench verwechselt werden sollte. Der coding-oriented SaaSBench benchmark ist ein anderer benchmark, der auf komplexe Software-Engineering-Aufgaben fokussiert ist.3 Sein berichtetes Setup umfasst 30 complex tasks, 5,370 validation nodes, 8 languages, 6 databases und 13 frameworks, wobei mehr als 95% der failures auftreten, bevor agents tiefe business logic erreichen.3
Die beiden benchmarks sind verschieden, aber das parallele Signal ist nützlich. Ob die Umgebung professionelle SaaS operations oder multi-service software engineering ist: Viele failures passieren, bevor das System die tiefste domain reasoning erreicht. Agents brechen an scaffolding: setup, state, dependencies, interfaces, validation und recovery.
Das macht Modellfortschritt nicht irrelevant. Es verändert, womit Modellfortschritt kombiniert werden muss.
Die Produktschicht wird zum Agent Harness
Die agent industry bewegt sich von einem Modellrennen zu einem Rennen der Ausführungssysteme.
Ein guter harness ist nicht nur eine Sammlung von Tools. Er ist eine workspace-level Produktschicht, die agent work inspectable und governable macht. Er sollte dem Nutzer helfen zu verstehen, was der agent tut, was er bereits getan hat, welche evidence completion stützt und wo human judgment erforderlich ist.
Für SaaS-Bench-artige Workflows braucht die harness layer mehrere Eigenschaften.
State continuity. Lange Workflows brauchen mehr als context stuffing. Das System muss den Unterschied zwischen user instruction, model hypothesis, observed UI state, saved artifact und verified decision kennen.
Checkpoint-aware execution. Wenn die Aufgabe von einer Sequenz von outcomes abhängt, sollte der workspace explizite verification fördern. Teilfortschritt sollte sichtbar sein, aber nicht mit completion verwechselt werden.
Permission and action boundaries. Professionelle SaaS-Workflows betreffen oft records, invoices, medical administration, team documents oder external communication. Ein ausgereiftes agent system braucht sichtbare approval points und sichere defaults, besonders bei irreversible oder externally visible actions.
Recovery rather than collapse. Wenn sich die UI ändert oder ein tool ausfällt, sollte das System nicht einfach weiter Fortschritt halluzinieren. Es sollte uncertainty erkennen, failure evidence bewahren, sicher retry ausführen oder den Nutzer um eine decision bitten.
Artifact-first output. Das Endprodukt professioneller Arbeit ist selten eine chat answer. Es ist ein report, ticket, spreadsheet, submitted form, document revision, media asset oder decision record. Ein harness sollte diese als durable objects behandeln.
Workspace orchestration. Viele Workflows sind zu breit für einen monolithischen thread. Research, execution, verification und final reporting können in sessions oder workstreams getrennt und dann von einem workspace-level coordinator zusammengeführt werden.
Darum konvergieren "agent harness" und "AI workspace". Der harness gibt dem Modell Hände, guardrails, memory und inspection. Der workspace gibt dem Nutzer einen Ort, um die Arbeit zu beaufsichtigen, zu organisieren und fortzusetzen.
Wo MCPlato hineinpasst
SaaS-Bench sollte nicht als Behauptung gelesen werden, dass irgendein einzelner workspace autonome SaaS-Arbeit gelöst hat. MCPlato hat nicht öffentlich behauptet, SaaS-Bench auszuführen oder die failure modes des benchmarks zu eliminieren. Die verantwortliche Schlussfolgerung ist enger und praktischer: Der benchmark bestätigt, warum workspace architecture wichtig ist.
MCPlato ist um die Idee herum gestaltet, dass ernsthafte agent work mehr braucht als ein einzelnes chat transcript. Auf hoher Ebene gibt es Nutzern eine Möglichkeit, agent execution durch workspaces, sessions, connected materials, visible artifacts und supervised continuation zu organisieren.
Mehrere MCPlato-Konzepte passen natürlich zur SaaS-Bench-Lektion:
- Multi-session orchestration. Lange professionelle Arbeit zerfällt oft in research, execution, review und synthesis. Separate sessions helfen, Grenzen zu bewahren, während der Nutzer weiterhin das Gesamtziel koordinieren kann.
- Sprite / virtual partner. Ein workspace-level partner kann helfen zu verfolgen, was active, blocked, complete ist und was noch review braucht. Der Wert liegt in orchestration, nicht in Theatralik.
- Artifact discipline. Outputs sollten zu prüfbaren deliverables werden: documents, reports, plans, diagrams, code changes oder andere files, die außerhalb des chat flow geprüft werden können.
- Local-first connected materials. Echte Arbeit hängt von local documents, project folders, notes und source materials ab. Ein workspace, der diese materials nah an der task hält, kann context loss reduzieren.
- Scheduled and background tasks. Manche agent work profitiert von continuation außerhalb eines einzelnen synchronen chat turn, besonders wenn research, checking oder batch production beteiligt sind.
- Permissioned and observable execution. Nutzer sollten sehen können, welche actions versucht wurden, und entscheiden können, wann ein step approval benötigt, besonders wenn der agent external systems oder durable artifacts berührt.
- Decision trace. Lange Workflows brauchen ein Gedächtnis dafür, was accepted, rejected, deferred wurde und warum. Ohne diese trace kann ein späterer agent step versehentlich die rationale eines früheren Schritts rückgängig machen.
Die wichtige Formulierung lautet "organisieren und beaufsichtigen helfen". Ein workspace harness macht nicht jeden agent standardmäßig autonomous, correct oder safe. Er gibt dem Nutzer und dem agent eine bessere execution surface: eine, auf der state, artifacts, permissions und recovery Teil der product experience sind, statt in einem transcript verborgen zu bleiben.
Was SaaS-Bench über die nächste Agent-Welle andeutet
Der benchmark weist auf eine realistischere Definition von agent progress hin.
Das nächste nützliche agent system wird nicht nur danach beurteilt, wie flüssig es in Text reasoning betreibt. Es wird danach beurteilt, ob es continuity über Anwendungen hinweg halten, evidence bewahren, sich von partial failures erholen, zur richtigen Zeit permission einholen und artifacts erzeugen kann, denen ein Profi vertrauen kann.
Das ist eine höhere Messlatte als "das Modell kann tools aufrufen". Tool use ist nur das interface. Die Produktfrage lautet, ob der umgebende harness tool use über lange Workflows hinweg reliable machen kann.
SaaS-Bench gibt der Branche ein schärferes Vokabular für diese Lücke:
- checkpoint progress ist nicht dasselbe wie resolved completion;
- browser control ist nicht dasselbe wie professional workflow delivery;
- model reasoning ist nicht dasselbe wie agent execution;
- ein chat transcript ist nicht dasselbe wie ein workspace;
- autonomy ohne observability ist keine product strategy.
Die Schlussfolgerung ist nicht, dass größere Modelle unwichtig sind. Sie sind wichtig. Aber wenn Modelle besser werden, werden die verbleibenden failures zunehmend architectural. Die Wettbewerbsfront verschiebt sich zu harnesses, workspaces, verification loops, permission models und artifact systems.
Das Modellrennen läuft weiter. SaaS-Bench deutet an, dass das nächste Rennen das execution-system race ist.
References
Footnotes
-
SaaS-Bench arXiv paper und SaaS-Bench HTML version, einschließlich title, authors, task composition, multi-application statistics, workflow-step statistics, scoring definitions und Table 2 benchmark scores, die in diesem Artikel zitiert werden. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
Official SaaS-Bench benchmark page and live leaderboard, einschließlich der offiziellen live leaderboard scores und der angegebenen 3,971 weighted checkpoints. ↩ ↩2 ↩3 ↩4
-
SaaSBench coding benchmark arXiv paper. Dies ist ein anderer benchmark als SaaS-Bench; er wird nur als Hintergrund-Vergleichssignal zitiert. ↩ ↩2