为什么 SaaS-Bench 表明 AI Agent 需要 Harness,而不只是更大的模型
SaaS-Bench 在真实专业 SaaS 工作流中测试 computer-use agents,并揭示了部分进展与已验证完成之间的差距。结果指向 agent harness、workspace state、verification、permissions 和 recovery 作为下一层产品能力。
发布于 2026-05-25
低于 4%,这是令人不安的头条结论。
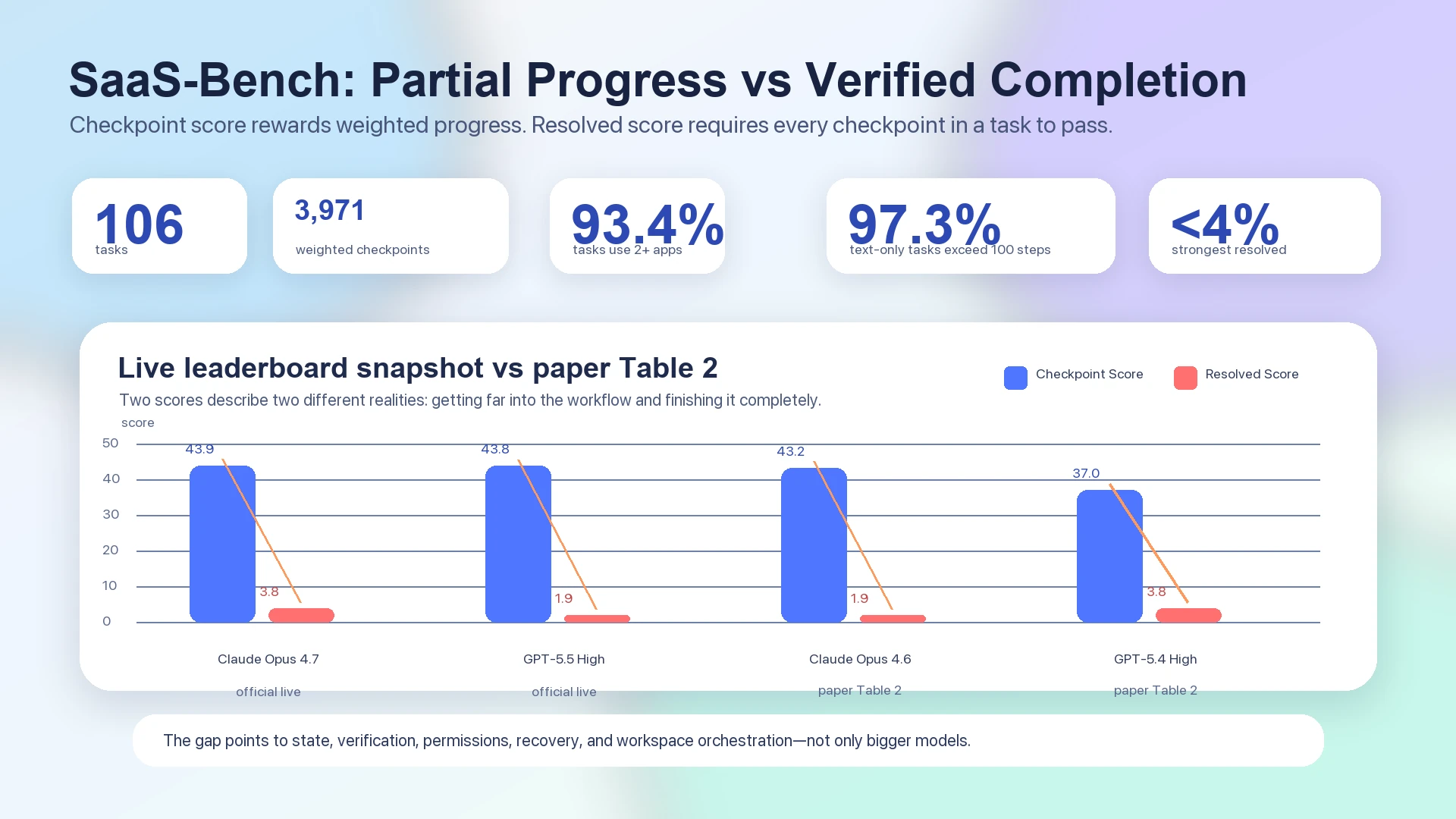
在 SaaS-Bench 论文中,最强的端到端 Resolved Score 仍低于 4%:Table 2 报告 Claude Opus 4.6 的整体 checkpoint score 为 43.2、resolved score 为 1.9,而 GPT-5.4 High 的整体 checkpoint score 为 37.0、resolved score 为 3.8。1 官方实时排行榜应与静态论文表格分开看待;它同样显示,顶尖系统的 checkpoint score 聚集在 40 分出头,但 resolved score 仍落在 3.8 或 1.9:Claude Opus 4.7 为 43.9 checkpoint / 3.8 resolved,GPT-5.5 High 为 43.8 checkpoint / 1.9 resolved。2
这个差距才是故事本身。Computer-use agents 可以在漫长的 SaaS 工作流中取得可见进展,但它们很少能把工作流一路推进到已验证完成。瓶颈不只是模型智能,而是模型周围缺失的执行系统:state、verification、permissions、recovery、artifacts 和 workspace orchestration。
因此,SaaS-Bench 的价值不在于宣告 agents 很弱,而在于澄清 agents 现在需要哪一种产品层。
SaaS-Bench 测量什么
SaaS-Bench 的标题是 “SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows?” 作者包括 Kean Shi、Zihang Li、Tianyi Ma、Zengji Tu、Jialong Wu、Xinbo Xu、Qingyao Yang、Ruoyu Wu、Weichu Xie、Ming Wu、Jason Zeng、Michael Heinrich、Elvis Zhang、Liang Chen、Kuan Li 和 Baobao Chang。1
该 benchmark 在 23 个可部署的开源 SaaS 系统上评估 agents,覆盖 6 个专业领域和 106 项任务。1 这些领域包括 Software Engineering & Project Management、Business Operations & Finance、Healthcare Administration、Team Collaboration & Document Workflow、Artisan Agri-Food Supply Chain,以及 Independent Media Creation。1
这一点很重要。这个 benchmark 不是狭窄的浏览器点击玩具。它更接近人类专业人员在文档、项目看板、仪表盘、表单、日历、财务系统和媒体工具之间切换时所执行的运营性工作。
任务分布让这一点更加具体。SaaS-Bench 包含 74 个纯文本任务和 32 个多模态任务。1 它也强调跨应用工作:106 个任务中有 99 个,也就是 93.4%,涉及至少 2 个应用;53 个任务,也就是 50.0%,涉及 3 个应用。1 工作流也很长:74 个纯文本任务中有 72 个,也就是 97.3%,超过 100 步;32 个多模态任务中有 19 个,也就是 61.3%,超过 100 步。1
官方 benchmark 页面称,该套件包含 3,971 个加权 verification checkpoints。2 评分设计很关键:Checkpoint Score 衡量加权的部分进展,而 Resolved Score 要求某个任务的所有 checkpoints 都通过。2 换句话说,这个 benchmark 不只是问:“agent 看起来忙了吗?” 它问的是:“专业工作流是否真的以已验证状态结束?”
Checkpoint / Resolved 差距是核心信号
最能说明问题的 SaaS-Bench 结果并不是 agents 得分为零。它们并没有。更强的系统可以获得有意义的 checkpoint 分数。它们能够导航、阅读、输入、搜索、总结,有时还能恢复到足以满足许多中间条件的状态。
问题在于,专业工作流具有乘法效应。如果一个任务有许多相互依赖的步骤,少量小缺陷就可能让最终结果不可用。漏掉一个权限步骤、带着陈旧 state 继续、更新了错误的 SaaS 记录、未能验证上传的 artifact,或遗失跨应用依赖关系,即使已有可见进展,也可能让工作流仍未 resolved。
 展示 SaaS-Bench 中 checkpoint progress 与 verified completion 差距的数据断裂图
展示 SaaS-Bench 中 checkpoint progress 与 verified completion 差距的数据断裂图
图:SaaS-Bench 数据将部分进展与已验证完成区分开来。论文 Table 2 和官方实时排行榜都显示,checkpoint scores 远高于 resolved scores。12
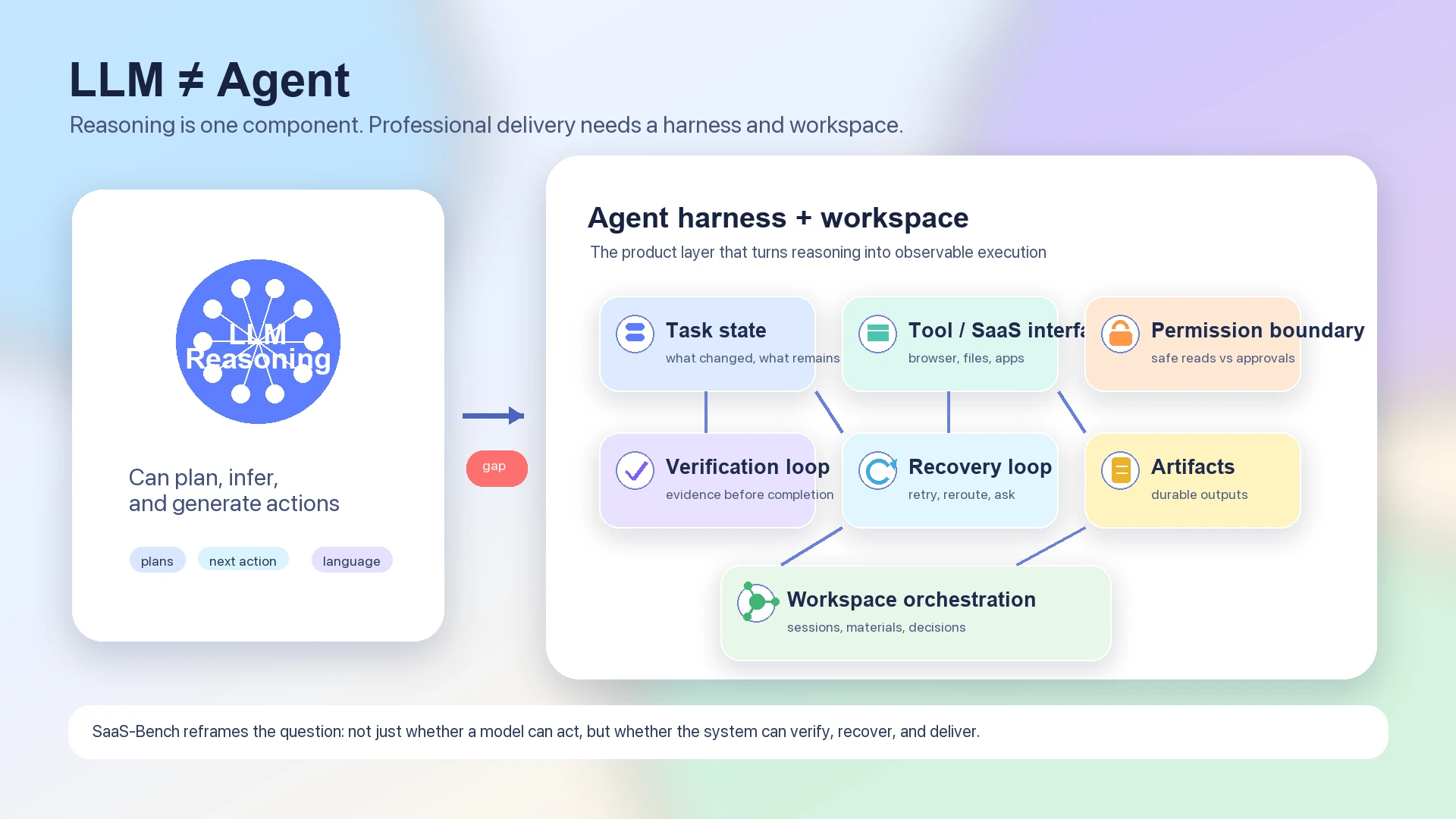
这就是为什么该 benchmark 更适合用来讨论 agent 架构,而不是简单做模型排名。纯 LLM 可以规划、推理并生成下一步行动。但一个能工作的 agent 还必须在许多步骤之间保存 state,验证外部世界是否按预期变化,知道何时请求 permission,安全重试,并留下可检查的 artifacts。
模型是推理引擎。Harness 是执行系统。
LLM 不等于 Agent
“AI agent” 这个短语常常把多个层次压缩成一个词。SaaS-Bench 让这种压缩更难成立。
语言模型可以生成这样的计划:“打开 CRM,更新客户记录,附上已签署文档,通知团队,并核对发票。” 但专业工作流需要的不只是计划。系统必须知道哪个浏览器 state 是当前的,哪个 SaaS app 是权威来源,哪个文件是记录中的 artifact,哪个动作可逆,哪个动作需要用户批准,以及哪个 checkpoint 能证明任务已经完成。
 LLM 是更大 agent harness 与 workspace architecture 中的一个组成部分
LLM 是更大 agent harness 与 workspace architecture 中的一个组成部分
因此,一个有用的 agent stack 至少包含这些层:
| 层 | 贡献 |
|---|---|
| LLM reasoning | 解读目标、起草计划、选择下一步行动,并解释权衡。 |
| Task state | 跟踪已完成事项、仍待处理事项,以及哪些假设尚未验证。 |
| Tool and SaaS interface | 将浏览器操作、文档、文件、SaaS 系统和外部工具连接成可用能力。 |
| Permission boundary | 区分安全的只读操作与需要明确批准或监督的操作。 |
| Verification loop | 检查每个重要 state transition 是否真的发生。 |
| Recovery loop | 处理失败、重试、部分完成、UI state 变化和意外结果。 |
| Artifact discipline | 产出持久的文档、记录、表格、ticket、报告或代码变更,而不仅是 chat replies。 |
| Workspace orchestration | 随时间协调多个 sessions、materials、decisions 和 follow-up tasks。 |
当这些层较弱时,更强的模型仍可能失败。它可能在抽象层面推理正确,却随后失去对具体世界的跟踪。它可能完成了大多数可见步骤,却仍漏掉定义成功的那个验证条件。它可能具备长推理能力,却缺少用于长期运行工作的安全机制。
SaaS-Bench 间接测量了这些缺失层。Checkpoint score 表明模型可以做出贡献。Resolved score 表明仅有这种贡献还不够。
失败不只是“模型智能”问题
人们很容易把 benchmark 表格解读为模型竞赛。这部分成立,但并不完整。
对于短任务,模型质量可能占主导。如果工作只是一个单次回答,最强的推理模型通常会胜出。对于漫长的 SaaS 工作流,失败分布会改变。Agent 必须在一个有 state、有 permissions、异步且不一致的世界里行动。浏览器可能没有显示预期元素。文档可能被保存到错误位置。SaaS 表单可能需要隐藏校验。通知可能必须引用正确的 artifact。某个工作流可能要求在后续步骤改变所需输出后,回到之前的 app。
这些既是 harness 问题,也是推理问题。
更强的模型也许能选择更好的动作,但它仍然需要一个能够回答运营性问题的环境:
- 当前的 source of truth 是什么?
- 上一个动作之后发生了什么变化?
- 哪个 checkpoint 有证据,哪个 checkpoint 只是被假定完成?
- 哪一步可以安全重试?
- 哪个操作需要用户批准?
- 哪个 artifact 应该作为最终结果移交?
- 哪种失败应该触发 recovery,而不是继续执行?
这就是能够描述工作的 chatbot 与能够交付工作的 agent system 之间的区别。
来自另一个 SaaSBench 的平行信号
还有另一个名称相似的 benchmark,不应与 SaaS-Bench 混淆。面向 coding 的 SaaSBench benchmark 是一个不同的 benchmark,聚焦复杂软件工程任务。3 其报告的设置包括 30 个复杂任务、5,370 个 validation nodes、8 种语言、6 个数据库和 13 个框架,并且超过 95% 的失败发生在 agents 触及深层业务逻辑之前。3
两个 benchmark 并不相同,但这个平行信号很有用。无论环境是专业 SaaS 运营,还是多服务软件工程,许多失败都发生在系统触及最深层领域推理之前。Agents 会在脚手架层面出问题:setup、state、dependencies、interfaces、validation 和 recovery。
这并不意味着模型进步无关紧要。它改变的是模型进步必须与什么配套。
产品层正在变成 Agent Harness
Agent 行业正在从模型竞赛转向执行系统竞赛。
一个好的 harness 不只是工具集合。它是 workspace 级别的产品层,使 agent work 可检查、可治理。它应该帮助用户理解 agent 正在做什么、已经做了什么、哪些证据支持完成,以及哪些地方需要人类判断。
对于 SaaS-Bench 这类工作流,harness 层需要具备几项属性。
State continuity. 长工作流需要的不只是 context stuffing。系统需要知道用户指令、模型假设、已观察到的 UI state、已保存 artifact 和已验证 decision 之间的区别。
Checkpoint-aware execution. 如果任务依赖一系列结果,workspace 应鼓励显式验证。部分进展应该可见,但不应与完成混淆。
Permission and action boundaries. 专业 SaaS 工作流通常涉及记录、发票、医疗行政、团队文档或外部沟通。成熟的 agent system 需要可见的 approval points 和安全默认值,尤其是在不可逆或对外可见的动作周围。
Recovery rather than collapse. 当 UI 变化或工具失败时,系统不应只是继续幻觉式地推进进度。它应该检测不确定性,保留失败证据,安全重试,或向用户请求决策。
Artifact-first output. 专业工作的最终产物很少是 chat answer。它可能是报告、ticket、spreadsheet、已提交表单、文档修订、媒体资产或决策记录。Harness 应该把这些视为持久对象。
Workspace orchestration. 许多工作流对一个单体线程来说过于宽泛。Research、execution、verification 和 final reporting 可以拆分为 sessions 或 workstreams,再由 workspace 级 coordinator 进行协调。
这就是为什么 “agent harness” 与 “AI workspace” 正在融合。Harness 给模型提供双手、guardrails、memory 和 inspection。Workspace 给用户一个监督、组织并延续工作的地方。
MCPlato 适合放在哪里
不应把 SaaS-Bench 解读为某个 workspace 已经解决了自主 SaaS 工作。MCPlato 并未公开声称运行过 SaaS-Bench,也未声称消除了该 benchmark 的失败模式。更负责的结论更窄,也更实际:这个 benchmark 验证了为什么 workspace architecture 很重要。
MCPlato 的设计围绕一个理念:严肃的 agent work 需要的不只是单一 chat transcript。从高层看,它为用户提供了一种通过 workspaces、sessions、connected materials、visible artifacts 和 supervised continuation 来组织 agent execution 的方式。
几个 MCPlato 概念可以自然映射到 SaaS-Bench 的启示:
- Multi-session orchestration. 漫长的专业工作通常会拆分为 research、execution、review 和 synthesis。分离的 sessions 有助于保持边界,同时仍允许用户协调总体目标。
- Sprite / virtual partner. Workspace 级 partner 可以帮助跟踪什么在进行中、什么被阻塞、什么已完成、什么仍需 review。价值在于 orchestration,而不是表演性。
- Artifact discipline. 输出应成为可检查的 deliverables:documents、reports、plans、diagrams、code changes,或其他可在 chat flow 之外审查的文件。
- Local-first connected materials. 真实工作依赖本地文档、项目文件夹、笔记和源材料。让这些 materials 贴近任务的 workspace 可以减少 context loss。
- Scheduled and background tasks. 某些 agent work 适合在单个同步 chat turn 之外继续,尤其是在涉及 research、checking 或 batch production 时。
- Permissioned and observable execution. 用户应该能看到哪些 actions 已经被尝试,并决定某一步何时需要 approval,尤其是在 agent 接触 external systems 或 durable artifacts 时。
- Decision trace. 长工作流需要记住什么被接受、拒绝、延期以及原因。没有这条 trace,后续 agent 步骤可能会意外推翻早先步骤的理由。
关键措辞是“帮助组织和监督”。Workspace harness 并不会让每个 agent 默认变得自主、正确或安全。它为用户和 agent 提供了更好的执行表面:state、artifacts、permissions 和 recovery 成为产品体验的一部分,而不是隐藏在 transcript 里。
SaaS-Bench 暗示下一波 Agent 会是什么样
这个 benchmark 指向了一个更现实的 agent progress 定义。
下一代有用的 agent system 不会只按它在文本中推理得多流畅来判断。它会按是否能够跨应用保持 continuity、保存 evidence、从部分失败中 recovery、在正确时间请求 permission,并产出专业人员可以信任的 artifacts 来判断。
这比“模型可以调用工具”门槛更高。Tool use 只是接口。产品问题在于周围的 harness 是否能让 tool use 在长工作流中变得可靠。
SaaS-Bench 给行业提供了更清晰的词汇来描述这个差距:
- checkpoint progress 不等于 resolved completion;
- browser control 不等于 professional workflow delivery;
- model reasoning 不等于 agent execution;
- chat transcript 不等于 workspace;
- 没有 observability 的 autonomy 不是产品策略。
结论并不是更大的模型不重要。它们当然重要。但随着模型改进,剩余失败越来越具有架构属性。竞争前沿正在转向 harnesses、workspaces、verification loops、permission models 和 artifact systems。
模型竞赛仍在继续。SaaS-Bench 暗示,下一场竞赛是执行系统竞赛。
参考资料
Footnotes
-
SaaS-Bench arXiv 论文和 SaaS-Bench HTML 版本,包括本文引用的标题、作者、任务组成、跨应用统计、工作流步骤统计、评分定义以及 Table 2 benchmark scores。 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
SaaS-Bench 官方 benchmark 页面与实时排行榜,包括官方实时排行榜分数以及所述的 3,971 个加权 checkpoints。 ↩ ↩2 ↩3 ↩4
-
SaaSBench coding benchmark arXiv 论文。这是一个不同于 SaaS-Bench 的 benchmark;本文仅将其作为背景对比信号引用。 ↩ ↩2