Por que o SaaS-Bench mostra que AI Agents precisam de Harnesses, não apenas de modelos maiores
O SaaS-Bench testa computer-use agents em workflows SaaS profissionais reais e expõe a lacuna entre progresso parcial e conclusão verificada. O resultado aponta para agent harnesses, workspace state, verification, permissions e recovery como a próxima camada de produto.
Publicado em 2026-05-25
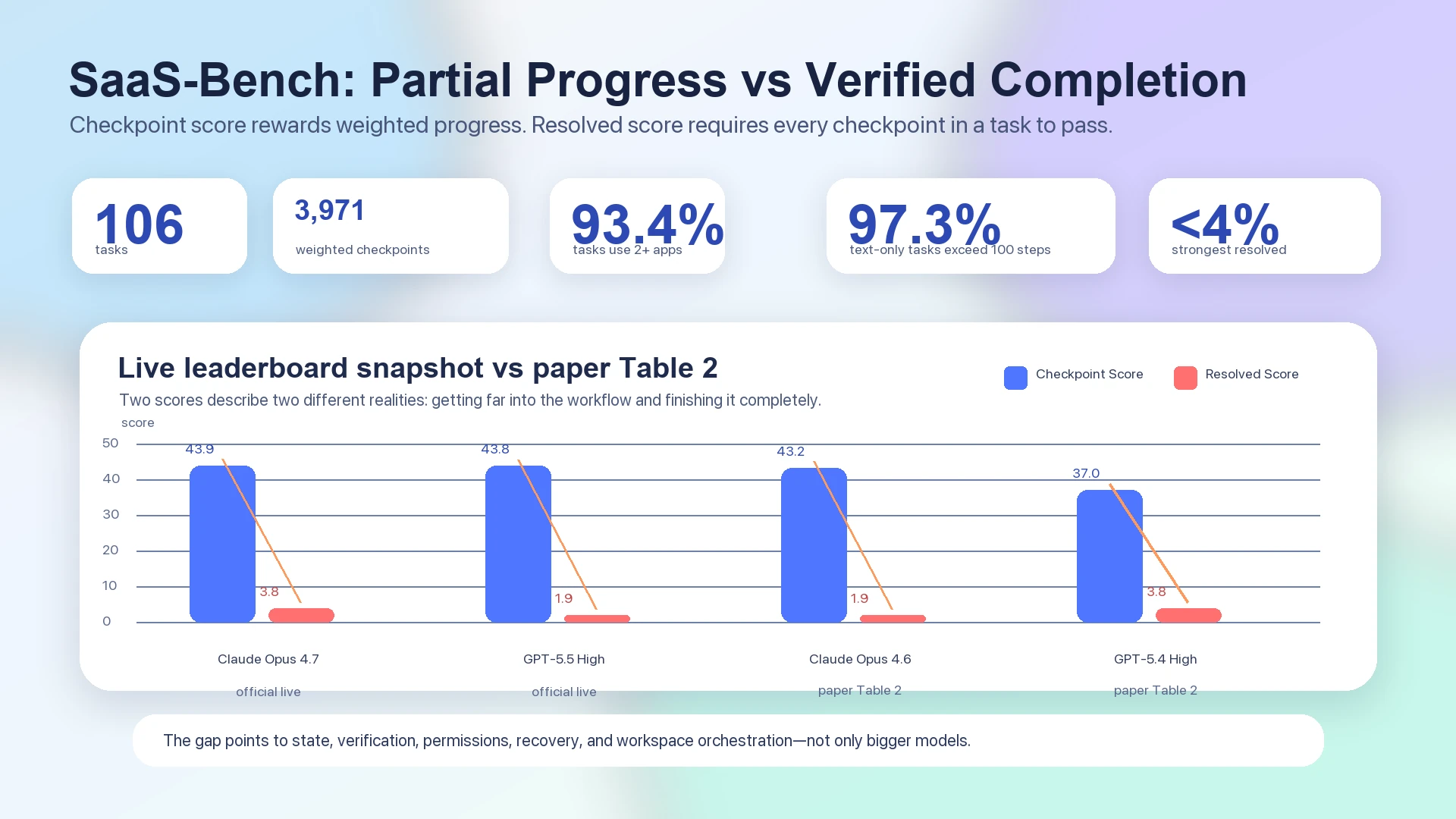
Menos de quatro por cento é a manchete incômoda.
No paper do SaaS-Bench, o melhor Resolved Score end-to-end continua abaixo de quatro por cento: o Claude Opus 4.6 é reportado na Table 2 com 43.2 de overall checkpoint score e 1.9 de resolved score, enquanto o GPT-5.4 High é reportado com 37.0 de overall checkpoint score e 3.8 de resolved score.1 O live leaderboard oficial, que deve ser tratado separadamente da tabela estática do paper, também mostrou sistemas de ponta agrupados nos baixos quarenta em checkpoint score, mas ainda chegando a 3.8 ou 1.9 de resolved score: Claude Opus 4.7 com 43.9 checkpoint / 3.8 resolved, e GPT-5.5 High com 43.8 checkpoint / 1.9 resolved.2
Essa lacuna é a história. Computer-use agents conseguem fazer progresso visível em workflows SaaS longos, mas raramente levam o workflow até uma conclusão verificada. O gargalo não é apenas a inteligência do modelo. É o sistema de execução ausente ao redor do modelo: state, verification, permissions, recovery, artifacts e workspace orchestration.
Portanto, o SaaS-Bench é útil não porque declara que agents são fracos, mas porque esclarece que tipo de camada de produto os agents agora precisam.
O que o SaaS-Bench mede
O SaaS-Bench tem o título “SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows?” Ele foi escrito por Kean Shi, Zihang Li, Tianyi Ma, Zengji Tu, Jialong Wu, Xinbo Xu, Qingyao Yang, Ruoyu Wu, Weichu Xie, Ming Wu, Jason Zeng, Michael Heinrich, Elvis Zhang, Liang Chen, Kuan Li e Baobao Chang.1
O benchmark avalia agents em 23 sistemas SaaS open-source implantáveis, em 6 domínios profissionais e 106 tarefas.1 Esses domínios são Software Engineering & Project Management, Business Operations & Finance, Healthcare Administration, Team Collaboration & Document Workflow, Artisan Agri-Food Supply Chain e Independent Media Creation.1
Isso é importante. O benchmark não é um brinquedo estreito de cliques no navegador. Ele está mais próximo do trabalho operacional que profissionais humanos realizam quando alternam entre documentos, project boards, dashboards, formulários, calendários, sistemas financeiros e ferramentas de mídia.
A distribuição de tarefas torna isso concreto. O SaaS-Bench inclui 74 text-only tasks e 32 multimodal tasks.1 Ele também enfatiza cross-application work: 99 de 106 tarefas, ou 93.4%, envolvem pelo menos 2 aplicações, enquanto 53 tarefas, ou 50.0%, envolvem 3 aplicações.1 Os workflows também são longos: 72 de 74 text-only tasks, ou 97.3%, ultrapassam 100 passos, e 19 de 32 multimodal tasks, ou 61.3%, ultrapassam 100 passos.1
A página oficial do benchmark diz que a suíte contém 3,971 weighted verification checkpoints.2 O desenho de scoring importa: Checkpoint Score mede progresso parcial ponderado, enquanto Resolved Score exige que todos os checkpoints de uma tarefa sejam aprovados.2 Em outras palavras, o benchmark não pergunta apenas: "O agent parecia ocupado?" Ele pergunta: "O workflow profissional realmente terminou em um estado verificado?"
A lacuna Checkpoint / Resolved é o sinal central
O resultado mais revelador do SaaS-Bench não é que agents fazem zero pontos. Eles não fazem. Os sistemas mais fortes acumulam crédito checkpoint significativo. Eles conseguem navegar, ler, inserir dados, pesquisar, resumir e às vezes se recuperar o suficiente para satisfazer muitas condições intermediárias.
O problema é que workflows profissionais são multiplicativos. Se uma tarefa tem muitos passos dependentes, alguns pequenos defeitos podem tornar o resultado final inutilizável. Perder uma permission step, carregar state obsoleto, atualizar o SaaS record errado, falhar ao validar um artifact enviado ou perder uma cross-app dependency pode deixar o workflow unresolved mesmo depois de progresso visível.
 Um diagrama de fratura de dados mostra a lacuna do SaaS-Bench entre checkpoint progress e verified completion
Um diagrama de fratura de dados mostra a lacuna do SaaS-Bench entre checkpoint progress e verified completion
Figura: Os dados do SaaS-Bench separam progresso parcial de conclusão verificada. A Table 2 do paper e o live leaderboard oficial mostram checkpoint scores muito mais altos que resolved scores.12
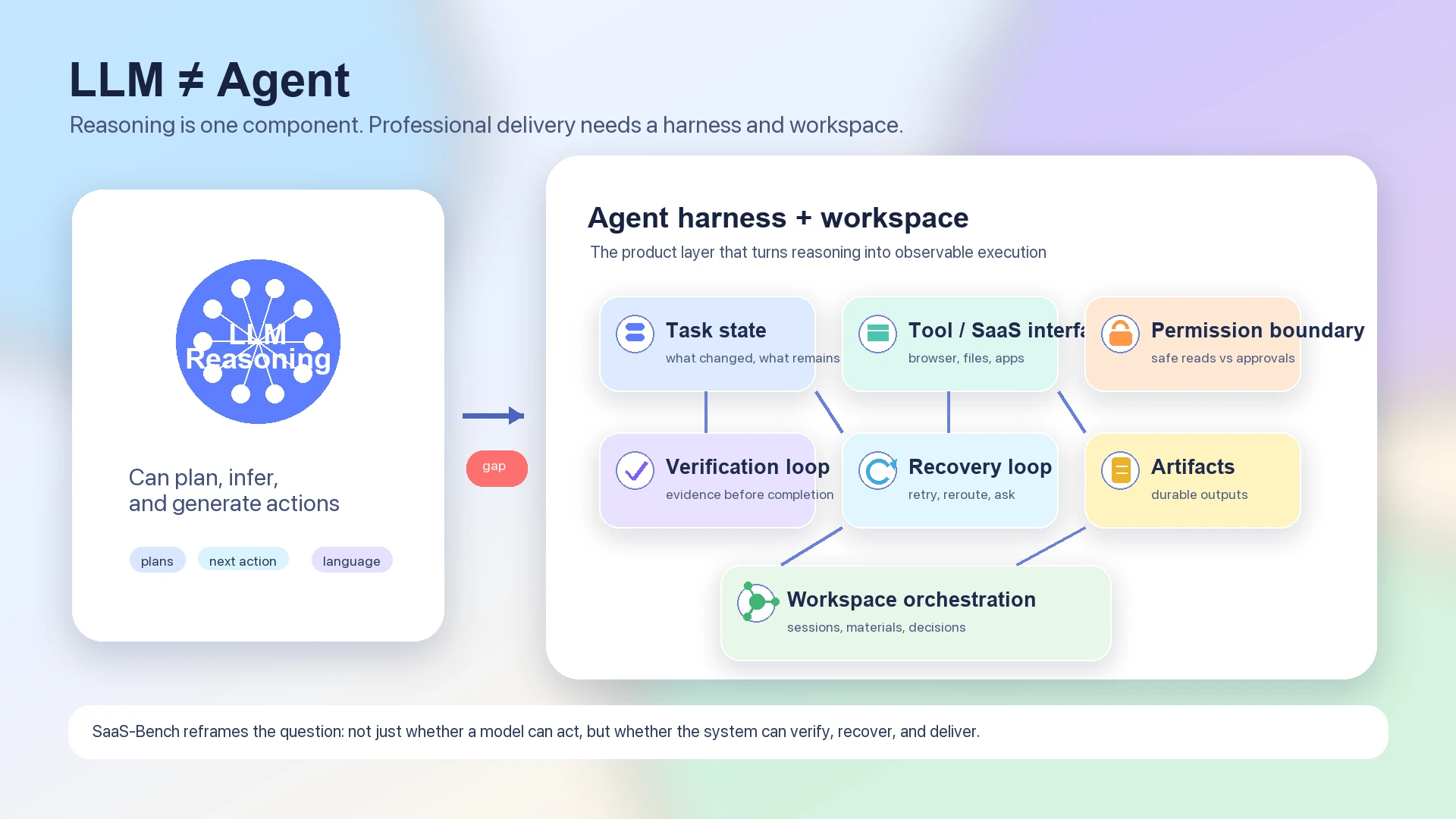
Por isso o benchmark combina melhor com uma discussão de agent architecture do que com um simples ranking de modelos. Um LLM puro pode planejar, raciocinar e gerar próximas actions. Mas um agent funcional também precisa preservar state ao longo de muitos passos, verificar se o mundo mudou como esperado, saber quando pedir permission, fazer retry com segurança e deixar artifacts que possam ser inspecionados.
O modelo é o motor de raciocínio. O harness é o sistema de execução.
LLM não é igual a Agent
A expressão "AI agent" muitas vezes comprime várias camadas em uma única palavra. O SaaS-Bench torna essa compressão mais difícil de defender.
Um modelo de linguagem pode produzir um plano como "abrir o CRM, atualizar o registro do cliente, anexar o documento assinado, notificar a equipe e reconciliar a fatura". Mas o workflow profissional exige mais do que um plano. Ele exige que o sistema saiba qual browser state é o atual, qual SaaS app é autoritativo, qual arquivo é o artifact of record, qual action é reversível, qual action precisa de user approval e qual checkpoint prova que a tarefa está completa.
 Um LLM é um componente dentro de uma agent harness e uma workspace architecture mais amplas
Um LLM é um componente dentro de uma agent harness e uma workspace architecture mais amplas
Um agent stack útil, portanto, tem pelo menos estas camadas:
| Camada | O que ela contribui |
|---|---|
| LLM reasoning | Interpreta objetivos, rascunha planos, escolhe próximas actions e explica trade-offs. |
| Task state | Acompanha o que foi feito, o que continua aberto e quais suposições ainda não foram verificadas. |
| Tool and SaaS interface | Conecta ações de navegador, documentos, arquivos, SaaS systems e ferramentas externas em capabilities utilizáveis. |
| Permission boundary | Distingue actions read-only seguras de actions que precisam de approval ou supervision explícita. |
| Verification loop | Verifica se cada state transition importante realmente aconteceu. |
| Recovery loop | Lida com failures, retries, partial completion, mudanças de UI state e resultados inesperados. |
| Artifact discipline | Produz documents, records, tables, tickets, reports ou code changes duráveis, não apenas chat replies. |
| Workspace orchestration | Coordena múltiplas sessions, materials, decisions e follow-up tasks ao longo do tempo. |
Quando essas camadas são fracas, um modelo mais forte ainda pode falhar. Ele pode raciocinar corretamente em abstrato e depois perder o controle do mundo concreto. Pode completar a maioria dos passos visíveis e ainda perder a verification condition que define sucesso. Pode ser capaz de long reasoning, mas não ter um mechanism seguro para long-running work.
O SaaS-Bench mede essas camadas ausentes indiretamente. O checkpoint score mostra que os modelos podem contribuir. O resolved score mostra que essa contribuição não é suficiente.
Falha não é apenas "inteligência do modelo"
É tentador ler tabelas de benchmark como uma corrida de modelos. Isso é parcialmente verdadeiro, mas incompleto.
Para tarefas curtas, a qualidade do modelo pode dominar. Se o trabalho é uma única resposta, o reasoning model mais forte costuma vencer. Para workflows SaaS longos, a distribuição das falhas muda. O agent precisa agir em um mundo stateful, permissioned, asynchronous e inconsistent. O navegador pode não mostrar o elemento esperado. Um documento pode ser salvo no lugar errado. Um formulário SaaS pode exigir uma validation oculta. Uma notificação pode precisar referenciar o artifact correto. Um workflow pode exigir voltar a uma app anterior depois que um passo posterior altera o output necessário.
Esses são harness problems tanto quanto reasoning problems.
Um modelo mais forte pode escolher actions melhores, mas ainda precisa de um ambiente que responda perguntas operacionais:
- Qual é a source of truth atual?
- O que mudou depois da última action?
- Qual checkpoint tem evidence e qual checkpoint é apenas assumed?
- Qual step é segura para retry?
- Qual operation exige user approval?
- Qual artifact deve ser entregue como resultado final?
- Qual failure deve acionar recovery em vez de continued execution?
Essa é a diferença entre um chatbot que consegue descrever trabalho e um agent system que consegue entregar trabalho.
Um sinal paralelo de outro SaaSBench
Há outro benchmark com nome parecido, e ele não deve ser confundido com o SaaS-Bench. O benchmark SaaSBench orientado a coding é um benchmark diferente, focado em tarefas complexas de software engineering.3 Sua configuração reportada inclui 30 complex tasks, 5,370 validation nodes, 8 languages, 6 databases e 13 frameworks, com mais de 95% das failures ocorrendo antes que agents cheguem à deep business logic.3
Os dois benchmarks são diferentes, mas o sinal paralelo é útil. Seja o ambiente professional SaaS operations ou multi-service software engineering, muitas failures acontecem antes que o sistema alcance o domain reasoning mais profundo. Agents quebram no scaffolding: setup, state, dependencies, interfaces, validation e recovery.
Isso não torna o progresso dos modelos irrelevante. Muda com o que o progresso dos modelos precisa ser combinado.
A camada de produto está virando o Agent Harness
A indústria de agents está saindo de uma corrida de modelos para uma corrida de sistemas de execução.
Um bom harness não é apenas uma coleção de tools. É uma camada de produto no nível do workspace que torna o agent work inspectable e governable. Ela deve ajudar o usuário a entender o que o agent está fazendo, o que já fez, que evidence sustenta a completion e onde human judgment é necessário.
Para workflows no estilo SaaS-Bench, a harness layer precisa de várias propriedades.
State continuity. Workflows longos exigem mais do que context stuffing. O sistema precisa saber a diferença entre uma user instruction, uma model hypothesis, um observed UI state, um saved artifact e uma verified decision.
Checkpoint-aware execution. Se a tarefa depende de uma sequência de outcomes, o workspace deve incentivar verification explícita. Progresso parcial deve ser visível, mas não deve ser confundido com completion.
Permission and action boundaries. Workflows SaaS profissionais muitas vezes envolvem records, invoices, medical administration, team documents ou external communication. Um agent system maduro precisa de approval points visíveis e defaults seguros, especialmente em torno de actions irreversíveis ou externally visible.
Recovery rather than collapse. Quando a UI muda ou uma tool falha, o sistema não deve simplesmente continuar alucinando progresso. Ele deve detectar uncertainty, preservar failure evidence, fazer retry com segurança ou pedir uma decision ao usuário.
Artifact-first output. O produto final do trabalho profissional raramente é uma chat answer. É um report, ticket, spreadsheet, submitted form, document revision, media asset ou decision record. Um harness deve tratar isso como durable objects.
Workspace orchestration. Muitos workflows são amplos demais para um thread monolítico. Research, execution, verification e final reporting podem ser separados em sessions ou workstreams, e depois reconciliados por um workspace-level coordinator.
É por isso que "agent harness" e "AI workspace" estão convergindo. O harness dá ao modelo hands, guardrails, memory e inspection. O workspace dá ao usuário um lugar para supervisionar, organizar e continuar o trabalho.
Onde o MCPlato se encaixa
O SaaS-Bench não deve ser lido como uma afirmação de que algum workspace resolveu o trabalho SaaS autônomo. O MCPlato não afirmou publicamente rodar o SaaS-Bench nem eliminar os failure modes do benchmark. A conclusão responsável é mais estreita e prática: o benchmark valida por que workspace architecture importa.
O MCPlato foi desenhado em torno da ideia de que agent work sério precisa de mais do que um único chat transcript. Em alto nível, ele oferece aos usuários uma forma de organizar agent execution por meio de workspaces, sessions, connected materials, visible artifacts e supervised continuation.
Vários conceitos do MCPlato se conectam naturalmente à lição do SaaS-Bench:
- Multi-session orchestration. Trabalho profissional longo muitas vezes se decompõe em research, execution, review e synthesis. Sessions separadas ajudam a preservar fronteiras enquanto ainda permitem ao usuário coordenar o objetivo geral.
- Sprite / virtual partner. Um workspace-level partner pode ajudar a acompanhar o que está active, blocked, complete e o que ainda precisa de review. O valor está na orchestration, não no teatro.
- Artifact discipline. Outputs devem se tornar deliverables inspecionáveis: documents, reports, plans, diagrams, code changes ou outros files que possam ser revisados fora do chat flow.
- Local-first connected materials. Trabalho real depende de local documents, project folders, notes e source materials. Um workspace que mantém esses materials perto da task pode reduzir context loss.
- Scheduled and background tasks. Alguns agent work se beneficiam de continuation fora de um único chat turn síncrono, especialmente quando research, checking ou batch production estão envolvidos.
- Permissioned and observable execution. Usuários devem conseguir ver quais actions foram tentadas e decidir quando uma step exige approval, especialmente quando o agent toca external systems ou durable artifacts.
- Decision trace. Workflows longos precisam de uma memória do que foi accepted, rejected, deferred e por quê. Sem essa trace, uma step posterior do agent pode desfazer acidentalmente a rationale de uma etapa anterior.
A formulação importante é "ajuda a organizar e supervisionar". Um workspace harness não torna todo agent autonomous, correct ou safe por padrão. Ele dá ao usuário e ao agent uma execution surface melhor: uma em que state, artifacts, permissions e recovery fazem parte da product experience, em vez de ficarem escondidos dentro de um transcript.
O que o SaaS-Bench sugere sobre a próxima onda de Agents
O benchmark aponta para uma definição mais realista de agent progress.
O próximo agent system útil não será julgado apenas pela fluência com que raciocina em texto. Será julgado por conseguir manter continuity entre aplicações, preservar evidence, recuperar-se de partial failures, pedir permission na hora certa e produzir artifacts nos quais um profissional possa confiar.
Isso é uma barra mais alta do que "o modelo consegue chamar tools". Tool use é apenas a interface. A pergunta de produto é se o harness ao redor consegue tornar tool use reliable em workflows longos.
O SaaS-Bench dá à indústria um vocabulário mais preciso para essa lacuna:
- checkpoint progress não é o mesmo que resolved completion;
- browser control não é o mesmo que professional workflow delivery;
- model reasoning não é o mesmo que agent execution;
- um chat transcript não é o mesmo que um workspace;
- autonomy sem observability não é uma product strategy.
A conclusão não é que modelos maiores não importam. Eles importam. Mas, conforme os modelos melhoram, as failures restantes se tornam cada vez mais architectural. A fronteira competitiva se move para harnesses, workspaces, verification loops, permission models e artifact systems.
A corrida de modelos continua. O SaaS-Bench sugere que a próxima corrida é a de execution systems.
References
Footnotes
-
SaaS-Bench arXiv paper e SaaS-Bench HTML version, incluindo title, authors, task composition, multi-application statistics, workflow-step statistics, scoring definitions e Table 2 benchmark scores citados neste artigo. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
Official SaaS-Bench benchmark page and live leaderboard, incluindo os official live leaderboard scores e os 3,971 weighted checkpoints declarados. ↩ ↩2 ↩3 ↩4
-
SaaSBench coding benchmark arXiv paper. Este é um benchmark diferente do SaaS-Bench; ele é citado apenas como sinal de comparação de fundo. ↩ ↩2