Por qué SaaS-Bench muestra que los AI Agents necesitan Harnesses, no solo modelos más grandes
SaaS-Bench prueba computer-use agents en workflows SaaS profesionales reales y expone la brecha entre progreso parcial y finalización verificada. El resultado apunta a agent harnesses, workspace state, verification, permissions y recovery como la próxima capa de producto.
Publicado el 2026-05-25
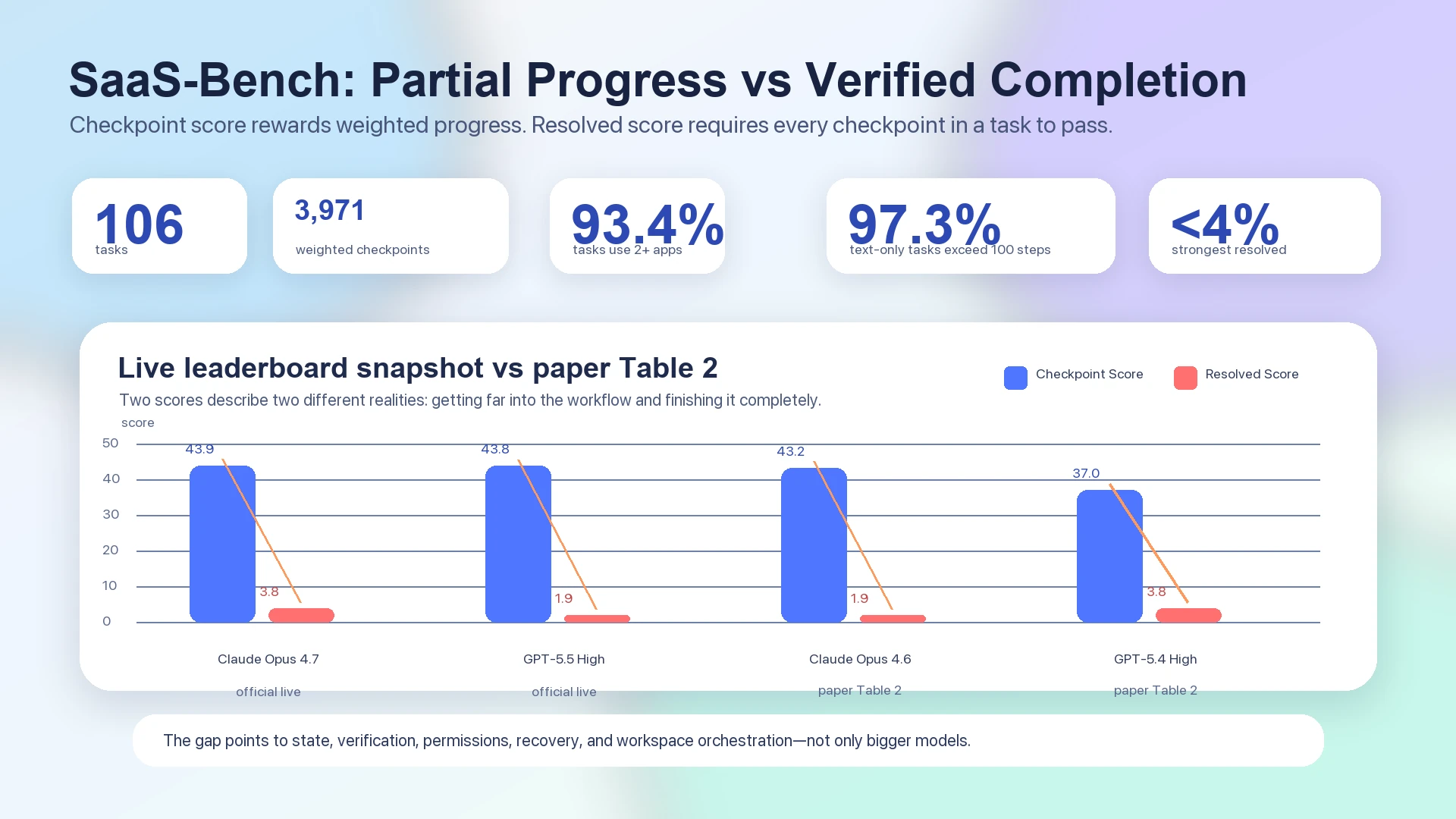
Menos del cuatro por ciento es el titular incómodo.
En el paper de SaaS-Bench, el mejor Resolved Score end-to-end sigue por debajo del cuatro por ciento: Claude Opus 4.6 aparece en la Table 2 con 43.2 de overall checkpoint score y 1.9 de resolved score, mientras que GPT-5.4 High aparece con 37.0 de overall checkpoint score y 3.8 de resolved score.1 El live leaderboard oficial, que debe tratarse por separado de la tabla estática del paper, también ha mostrado sistemas líderes agrupados alrededor de los cuarenta bajos en checkpoint score, pero todavía en 3.8 o 1.9 de resolved score: Claude Opus 4.7 con 43.9 checkpoint / 3.8 resolved, y GPT-5.5 High con 43.8 checkpoint / 1.9 resolved.2
Esa brecha es la historia. Los computer-use agents pueden lograr progreso visible en largos workflows SaaS, pero rara vez llevan el workflow hasta una finalización verificada. El cuello de botella no es solo la inteligencia del modelo. Es el sistema de ejecución que falta alrededor del modelo: state, verification, permissions, recovery, artifacts y workspace orchestration.
Por eso SaaS-Bench es útil no porque declare que los agents son débiles, sino porque aclara qué tipo de capa de producto necesitan ahora.
Qué mide SaaS-Bench
SaaS-Bench se titula “SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows?” Sus autores son Kean Shi, Zihang Li, Tianyi Ma, Zengji Tu, Jialong Wu, Xinbo Xu, Qingyao Yang, Ruoyu Wu, Weichu Xie, Ming Wu, Jason Zeng, Michael Heinrich, Elvis Zhang, Liang Chen, Kuan Li y Baobao Chang.1
El benchmark evalúa agents en 23 sistemas SaaS open-source desplegables, en 6 dominios profesionales y 106 tareas.1 Esos dominios son Software Engineering & Project Management, Business Operations & Finance, Healthcare Administration, Team Collaboration & Document Workflow, Artisan Agri-Food Supply Chain e Independent Media Creation.1
Esto es importante. El benchmark no es un juguete estrecho de clics en el navegador. Está más cerca del trabajo operativo que realizan los profesionales humanos cuando se mueven entre documentos, project boards, dashboards, formularios, calendarios, sistemas financieros y herramientas de medios.
La distribución de tareas lo hace concreto. SaaS-Bench incluye 74 text-only tasks y 32 multimodal tasks.1 También enfatiza cross-application work: 99 de 106 tareas, o 93.4%, involucran al menos 2 aplicaciones, mientras que 53 tareas, o 50.0%, involucran 3 aplicaciones.1 Los workflows también son largos: 72 de 74 text-only tasks, o 97.3%, superan los 100 pasos, y 19 de 32 multimodal tasks, o 61.3%, superan los 100 pasos.1
La página oficial del benchmark dice que la suite contiene 3,971 weighted verification checkpoints.2 El diseño de scoring importa: Checkpoint Score mide progreso parcial ponderado, mientras que Resolved Score exige que todos los checkpoints de una tarea pasen.2 En otras palabras, el benchmark no pregunta solo: "¿El agent parecía ocupado?" Pregunta: "¿El workflow profesional terminó realmente en un estado verificado?"
La brecha Checkpoint / Resolved es la señal central
El resultado más revelador de SaaS-Bench no es que los agents obtengan cero. No lo hacen. Los sistemas más fuertes acumulan crédito checkpoint significativo. Pueden navegar, leer, introducir datos, buscar, resumir y a veces recuperarse lo suficiente para satisfacer muchas condiciones intermedias.
El problema es que los workflows profesionales son multiplicativos. Si una tarea tiene muchos pasos dependientes, unos pocos defectos pequeños pueden hacer que el resultado final no sirva. Omitir un permission step, arrastrar state obsoleto, actualizar el SaaS record equivocado, no validar un artifact subido o perder una cross-app dependency puede dejar el workflow unresolved incluso después de progreso visible.
 Un diagrama de fractura de datos muestra la brecha de SaaS-Bench entre checkpoint progress y verified completion
Un diagrama de fractura de datos muestra la brecha de SaaS-Bench entre checkpoint progress y verified completion
Figura: Los datos de SaaS-Bench separan el progreso parcial de la finalización verificada. La Table 2 del paper y el live leaderboard oficial muestran checkpoint scores mucho más altos que resolved scores.12
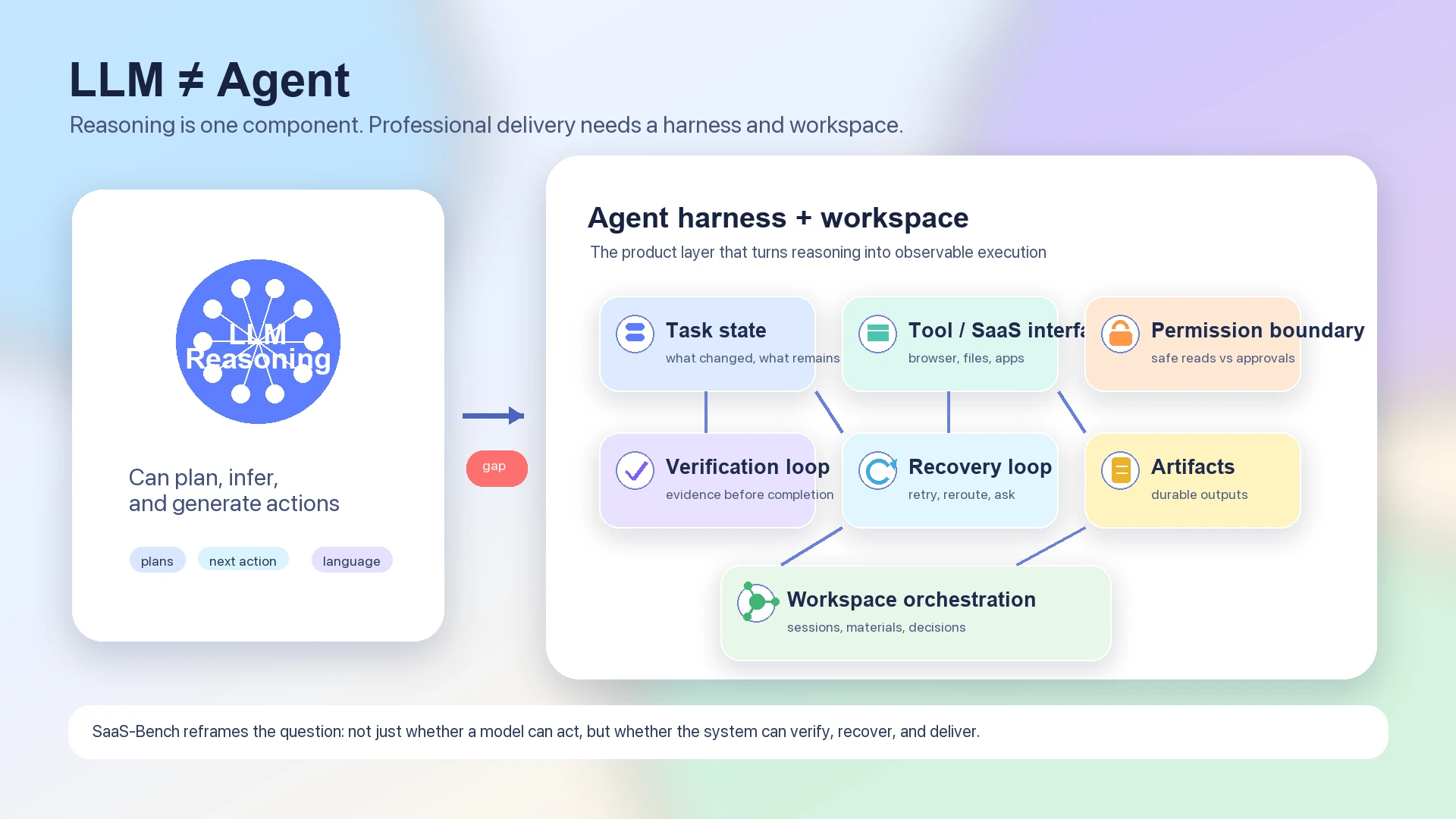
Por eso el benchmark encaja mejor con una discusión de agent architecture que con un ranking simple de modelos. Un LLM puro puede planificar, razonar y generar próximas actions. Pero un agent funcional también debe preservar state a través de muchos pasos, verificar si el mundo cambió como se esperaba, saber cuándo pedir permission, reintentar de forma segura y dejar artifacts que puedan inspeccionarse.
El modelo es el motor de razonamiento. El harness es el sistema de ejecución.
LLM no equivale a Agent
La frase "AI agent" suele colapsar varias capas en una sola palabra. SaaS-Bench hace que esa simplificación sea más difícil de defender.
Un modelo de lenguaje puede producir un plan como "abrir el CRM, actualizar el registro del cliente, adjuntar el documento firmado, notificar al equipo y conciliar la factura". Pero el workflow profesional requiere más que un plan. Requiere que el sistema sepa qué browser state está vigente, qué SaaS app es autoritativa, qué archivo es el artifact of record, qué action es reversible, qué action necesita user approval y qué checkpoint prueba que la tarea está completa.
 Un LLM es un componente dentro de una agent harness y una workspace architecture más amplias
Un LLM es un componente dentro de una agent harness y una workspace architecture más amplias
Un agent stack útil, por tanto, tiene al menos estas capas:
| Capa | Qué aporta |
|---|---|
| LLM reasoning | Interpreta objetivos, redacta planes, elige próximas actions y explica trade-offs. |
| Task state | Rastrea qué se ha hecho, qué sigue abierto y qué supuestos aún no están verificados. |
| Tool and SaaS interface | Conecta acciones del navegador, documentos, archivos, SaaS systems y herramientas externas en capabilities utilizables. |
| Permission boundary | Distingue acciones read-only seguras de actions que necesitan approval o supervision explícita. |
| Verification loop | Comprueba si cada state transition importante ocurrió realmente. |
| Recovery loop | Maneja failures, retries, partial completion, cambios de UI state y resultados inesperados. |
| Artifact discipline | Produce documents, records, tables, tickets, reports o code changes duraderos en lugar de solo chat replies. |
| Workspace orchestration | Coordina múltiples sessions, materials, decisions y follow-up tasks a lo largo del tiempo. |
Cuando estas capas son débiles, incluso un modelo más fuerte puede fallar. Puede razonar correctamente en abstracto y luego perder el rastro del mundo concreto. Puede completar la mayoría de los pasos visibles y aun así omitir la verification condition que define el éxito. Puede ser capaz de long reasoning pero carecer de un mechanism seguro para long-running work.
SaaS-Bench mide indirectamente esas capas faltantes. El checkpoint score muestra que los modelos pueden contribuir. El resolved score muestra que esa contribución no basta.
El fallo no es solo "inteligencia del modelo"
Es tentador leer las tablas de benchmark como una carrera de modelos. Eso es parcialmente cierto, pero incompleto.
Para tareas cortas, la calidad del modelo puede dominar. Si el trabajo es una sola respuesta, el reasoning model más fuerte suele ganar. Para workflows SaaS largos, la distribución de fallos cambia. El agent debe actuar en un mundo stateful, permissioned, asynchronous e inconsistent. El navegador puede no mostrar el elemento esperado. Un documento puede guardarse en el lugar equivocado. Un formulario SaaS puede requerir una validation oculta. Una notificación puede necesitar referenciar el artifact correcto. Un workflow puede exigir volver a una app anterior después de que un paso posterior cambie el output requerido.
Estos son harness problems tanto como reasoning problems.
Un modelo más fuerte puede elegir mejores actions, pero sigue necesitando un entorno que responda preguntas operativas:
- ¿Cuál es la source of truth actual?
- ¿Qué cambió después de la última action?
- ¿Qué checkpoint tiene evidence y cuál solo está assumed?
- ¿Qué step es seguro retry?
- ¿Qué operation requiere user approval?
- ¿Qué artifact debe entregarse como resultado final?
- ¿Qué failure debe activar recovery en lugar de continued execution?
Esta es la diferencia entre un chatbot que puede describir trabajo y un agent system que puede entregar trabajo.
Una señal paralela de otro SaaSBench
Hay otro benchmark con un nombre similar, y no debe confundirse con SaaS-Bench. El benchmark SaaSBench orientado a coding es un benchmark distinto, enfocado en tareas complejas de software engineering.3 Su configuración reportada incluye 30 complex tasks, 5,370 validation nodes, 8 languages, 6 databases y 13 frameworks, con más del 95% de los failures ocurriendo antes de que los agents alcancen deep business logic.3
Los dos benchmarks son diferentes, pero la señal paralela es útil. Ya sea que el entorno sea operaciones SaaS profesionales o multi-service software engineering, muchos failures ocurren antes de que el sistema llegue al domain reasoning más profundo. Los agents se rompen en el scaffolding: setup, state, dependencies, interfaces, validation y recovery.
Eso no vuelve irrelevante el progreso de los modelos. Cambia con qué debe emparejarse ese progreso.
La capa de producto se está convirtiendo en el Agent Harness
La industria de agents se está moviendo de una carrera de modelos a una carrera de sistemas de ejecución.
Un buen harness no es solo una colección de tools. Es una capa de producto a nivel de workspace que hace el agent work inspectable y governable. Debe ayudar al usuario a entender qué está haciendo el agent, qué ya hizo, qué evidence respalda la completion y dónde se requiere human judgment.
Para workflows tipo SaaS-Bench, la harness layer necesita varias propiedades.
State continuity. Los workflows largos requieren más que context stuffing. El sistema necesita conocer la diferencia entre una user instruction, una model hypothesis, un observed UI state, un saved artifact y una verified decision.
Checkpoint-aware execution. Si la tarea depende de una secuencia de outcomes, el workspace debe fomentar verification explícita. El progreso parcial debe ser visible, pero no debe confundirse con completion.
Permission and action boundaries. Los workflows SaaS profesionales suelen involucrar records, invoices, medical administration, team documents o external communication. Un agent system maduro necesita approval points visibles y defaults seguros, especialmente alrededor de actions irreversibles o externally visible.
Recovery rather than collapse. Cuando la UI cambia o falla una tool, el sistema no debe simplemente seguir alucinando progreso. Debe detectar uncertainty, preservar failure evidence, retry de forma segura o pedir una decision al usuario.
Artifact-first output. El producto final del trabajo profesional rara vez es una chat answer. Es un report, ticket, spreadsheet, submitted form, document revision, media asset o decision record. Un harness debe tratarlos como durable objects.
Workspace orchestration. Muchos workflows son demasiado amplios para un thread monolítico. Research, execution, verification y final reporting pueden separarse en sessions o workstreams y luego reconciliarse mediante un workspace-level coordinator.
Por eso "agent harness" y "AI workspace" están convergiendo. El harness le da al modelo manos, guardrails, memory e inspection. El workspace le da al usuario un lugar para supervisar, organizar y continuar el trabajo.
Dónde encaja MCPlato
SaaS-Bench no debe leerse como una afirmación de que un workspace haya resuelto el trabajo SaaS autónomo. MCPlato no ha afirmado públicamente ejecutar SaaS-Bench ni eliminar los failure modes del benchmark. La conclusión responsable es más estrecha y práctica: el benchmark valida por qué importa la workspace architecture.
MCPlato está diseñado alrededor de la idea de que el agent work serio necesita más que un único chat transcript. A alto nivel, ofrece a los usuarios una forma de organizar agent execution mediante workspaces, sessions, connected materials, visible artifacts y supervised continuation.
Varios conceptos de MCPlato encajan naturalmente con la lección de SaaS-Bench:
- Multi-session orchestration. El trabajo profesional largo suele descomponerse en research, execution, review y synthesis. Las sessions separadas ayudan a preservar límites mientras el usuario coordina el objetivo general.
- Sprite / virtual partner. Un workspace-level partner puede ayudar a rastrear qué está active, qué está blocked, qué está complete y qué aún necesita review. El valor es la orchestration, no el espectáculo.
- Artifact discipline. Los outputs deben convertirse en deliverables inspeccionables: documents, reports, plans, diagrams, code changes u otros files revisables fuera del chat flow.
- Local-first connected materials. El trabajo real depende de local documents, project folders, notes y source materials. Un workspace que mantiene esos materials cerca de la task puede reducir context loss.
- Scheduled and background tasks. Algunos agent work se benefician de continuation fuera de un único chat turn síncrono, especialmente cuando hay research, checking o batch production.
- Permissioned and observable execution. Los usuarios deben poder ver qué actions se intentaron y decidir cuándo una step requiere approval, especialmente cuando el agent toca external systems o durable artifacts.
- Decision trace. Los workflows largos necesitan una memoria de qué fue accepted, rejected, deferred y por qué. Sin esa trace, una step posterior del agent puede deshacer accidentalmente la rationale de una anterior.
La formulación importante es "ayuda a organizar y supervisar". Un workspace harness no vuelve a cada agent autonomous, correct o safe por defecto. Les da al usuario y al agent una mejor execution surface: una en la que state, artifacts, permissions y recovery son parte de la product experience, no algo escondido dentro de un transcript.
Lo que SaaS-Bench sugiere sobre la próxima ola de Agents
El benchmark apunta a una definición más realista de agent progress.
El próximo agent system útil no se juzgará solo por lo fluidamente que razona en texto. Se juzgará por si puede mantener continuity entre aplicaciones, preservar evidence, recuperarse de partial failures, pedir permission en el momento adecuado y producir artifacts en los que un profesional pueda confiar.
Eso es una vara más alta que "el modelo puede llamar tools". Tool use es solo la interfaz. La pregunta de producto es si el harness que lo rodea puede hacer que tool use sea reliable en workflows largos.
SaaS-Bench le da a la industria un vocabulario más preciso para esa brecha:
- checkpoint progress no es lo mismo que resolved completion;
- browser control no es lo mismo que professional workflow delivery;
- model reasoning no es lo mismo que agent execution;
- un chat transcript no es lo mismo que un workspace;
- autonomy sin observability no es una product strategy.
La conclusión no es que los modelos más grandes no importen. Sí importan. Pero a medida que los modelos mejoran, los failures restantes se vuelven cada vez más architectural. La frontera competitiva se mueve hacia harnesses, workspaces, verification loops, permission models y artifact systems.
La carrera de modelos continúa. SaaS-Bench sugiere que la próxima carrera es la de execution systems.
References
Footnotes
-
SaaS-Bench arXiv paper y SaaS-Bench HTML version, incluyendo title, authors, task composition, multi-application statistics, workflow-step statistics, scoring definitions y Table 2 benchmark scores citados en este artículo. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
Official SaaS-Bench benchmark page and live leaderboard, incluyendo los official live leaderboard scores y los 3,971 weighted checkpoints indicados. ↩ ↩2 ↩3 ↩4
-
SaaSBench coding benchmark arXiv paper. Este es un benchmark diferente de SaaS-Bench; se cita solo como señal de comparación de fondo. ↩ ↩2