لماذا يوضح SaaS-Bench أن AI Agents تحتاج إلى Harnesses، لا إلى نماذج أكبر فقط
يختبر SaaS-Bench computer-use agents على workflows SaaS مهنية حقيقية، ويكشف الفجوة بين التقدم الجزئي والإنجاز المتحقق منه. وتشير النتيجة إلى أن agent harnesses و workspace state و verification و permissions و recovery هي طبقة المنتج التالية.
نُشر في 2026-05-25
أقل من أربعة بالمئة هو العنوان المزعج.
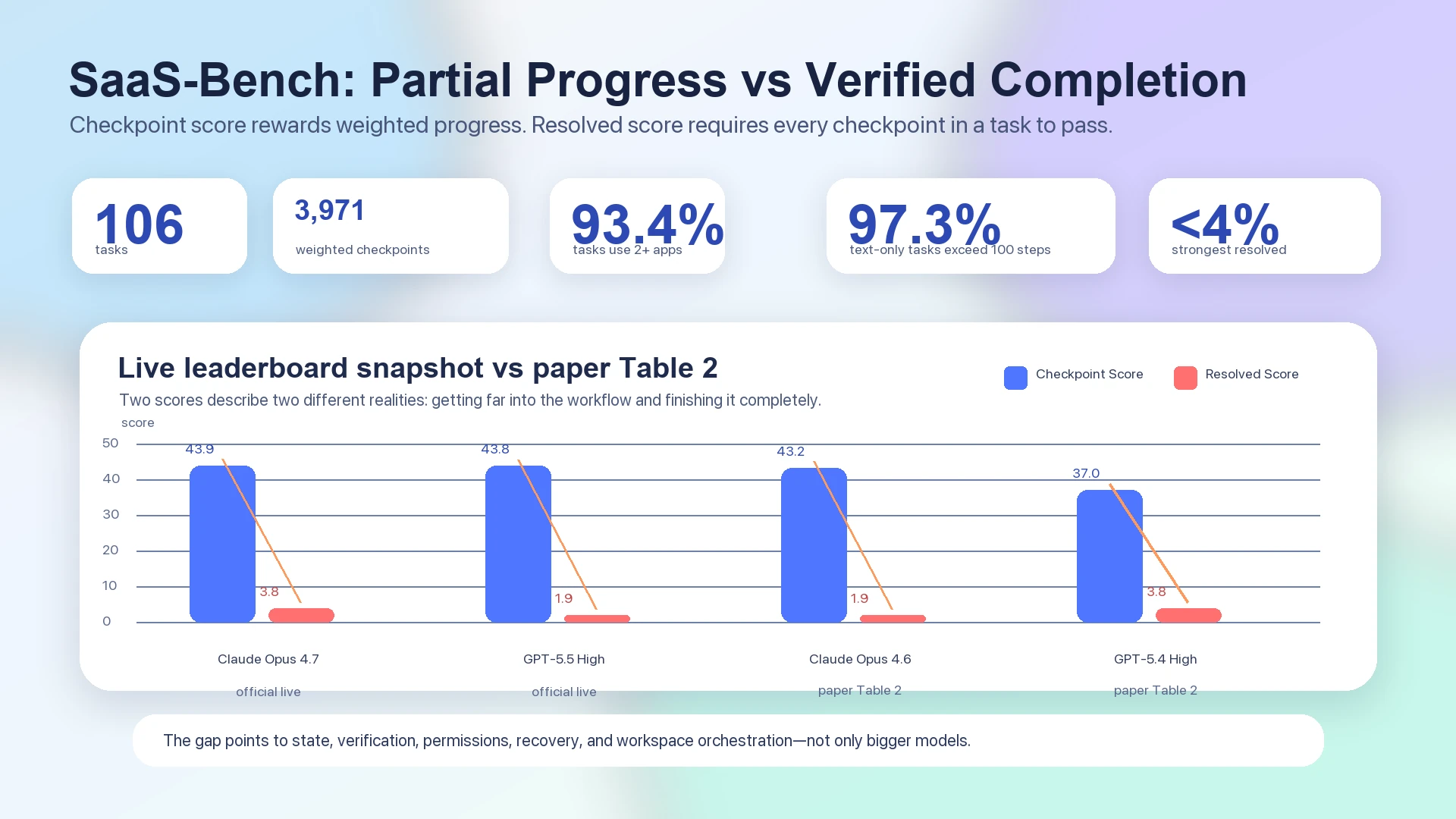
في ورقة SaaS-Bench، يبقى أقوى Resolved Score من البداية إلى النهاية دون أربعة بالمئة: يعرض Table 2 أن Claude Opus 4.6 حقق 43.2 في overall checkpoint score و 1.9 في resolved score، بينما يعرض أن GPT-5.4 High حقق 37.0 في overall checkpoint score و 3.8 في resolved score.1 أما live leaderboard الرسمي، الذي يجب التعامل معه بصورة منفصلة عن جدول الورقة الثابت، فقد أظهر أيضا أن الأنظمة المتقدمة تتجمع حول أوائل الأربعينات في checkpoint score بينما ما تزال تهبط عند 3.8 أو 1.9 في resolved score: Claude Opus 4.7 عند 43.9 checkpoint / 3.8 resolved، و GPT-5.5 High عند 43.8 checkpoint / 1.9 resolved.2
هذه الفجوة هي القصة. تستطيع computer-use agents تحقيق تقدم مرئي عبر workflows SaaS طويلة، لكنها نادرا ما تحمل workflow بالكامل إلى إنجاز متحقق منه. عنق الزجاجة ليس ذكاء النموذج فقط. إنه نظام التنفيذ المفقود حول النموذج: state و verification و permissions و recovery و artifacts و workspace orchestration.
لذلك فإن فائدة SaaS-Bench لا تأتي من إعلان أن agents ضعيفة، بل من توضيح نوع طبقة المنتج التي تحتاج إليها agents الآن.
ما الذي يقيسه SaaS-Bench
عنوان SaaS-Bench هو “SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows?” وقد كتبه Kean Shi و Zihang Li و Tianyi Ma و Zengji Tu و Jialong Wu و Xinbo Xu و Qingyao Yang و Ruoyu Wu و Weichu Xie و Ming Wu و Jason Zeng و Michael Heinrich و Elvis Zhang و Liang Chen و Kuan Li و Baobao Chang.1
يقيم benchmark أداء agents على 23 نظام SaaS مفتوح المصدر وقابل للنشر، عبر 6 مجالات مهنية و 106 مهام.1 هذه المجالات هي Software Engineering & Project Management و Business Operations & Finance و Healthcare Administration و Team Collaboration & Document Workflow و Artisan Agri-Food Supply Chain و Independent Media Creation.1
هذا مهم. فالbenchmark ليس لعبة ضيقة للنقر داخل المتصفح. إنه أقرب إلى العمل التشغيلي الذي يؤديه المهنيون عندما ينتقلون بين documents و project boards و dashboards و forms و calendars و finance systems و media tools.
تجعل توزيعة المهام ذلك واضحا. يتضمن SaaS-Bench 74 مهمة text-only و 32 مهمة multimodal.1 كما يركز على cross-application work: هناك 99 من أصل 106 مهام، أي 93.4%، تتضمن على الأقل 2 applications، بينما تتضمن 53 مهمة، أي 50.0%، 3 applications.1 والworkflows طويلة أيضا: 72 من أصل 74 مهمة text-only، أي 97.3%، تتجاوز 100 خطوة، و 19 من أصل 32 مهمة multimodal، أي 61.3%، تتجاوز 100 خطوة.1
تقول صفحة benchmark الرسمية إن الحزمة تحتوي على 3,971 weighted verification checkpoints.2 تصميم scoring مهم: يقيس Checkpoint Score التقدم الجزئي الموزون، بينما يتطلب Resolved Score أن تنجح كل checkpoints الخاصة بالمهمة.2 بعبارة أخرى، لا يسأل benchmark فقط: "هل بدا agent مشغولا؟" بل يسأل: "هل انتهى workflow المهني فعلا في حالة متحقق منها؟"
فجوة Checkpoint / Resolved هي الإشارة الأساسية
النتيجة الأكثر كشفا في SaaS-Bench ليست أن agents تسجل صفرا. فهي لا تفعل ذلك. الأنظمة الأقوى تجمع checkpoint credit معتبرا. يمكنها التنقل، والقراءة، والإدخال، والبحث، والتلخيص، وأحيانا recovery بما يكفي لتحقيق كثير من الشروط الوسيطة.
المشكلة أن workflows المهنية ذات طبيعة تضاعفية. إذا تضمنت المهمة خطوات كثيرة مترابطة، فقد تجعل بضعة عيوب صغيرة النتيجة النهائية غير صالحة للاستخدام. تفويت permission step واحدة، أو حمل state قديم، أو تحديث SaaS record الخطأ، أو الفشل في التحقق من artifact مرفوع، أو فقدان cross-app dependency، يمكن أن يترك workflow غير resolved حتى بعد تقدم مرئي.
 مخطط انقسام بيانات يوضح فجوة SaaS-Bench بين checkpoint progress و verified completion
مخطط انقسام بيانات يوضح فجوة SaaS-Bench بين checkpoint progress و verified completion
الشكل: تفصل بيانات SaaS-Bench بين التقدم الجزئي والإنجاز المتحقق منه. يظهر كل من Table 2 في الورقة و live leaderboard الرسمي أن checkpoint scores أعلى بكثير من resolved scores.12
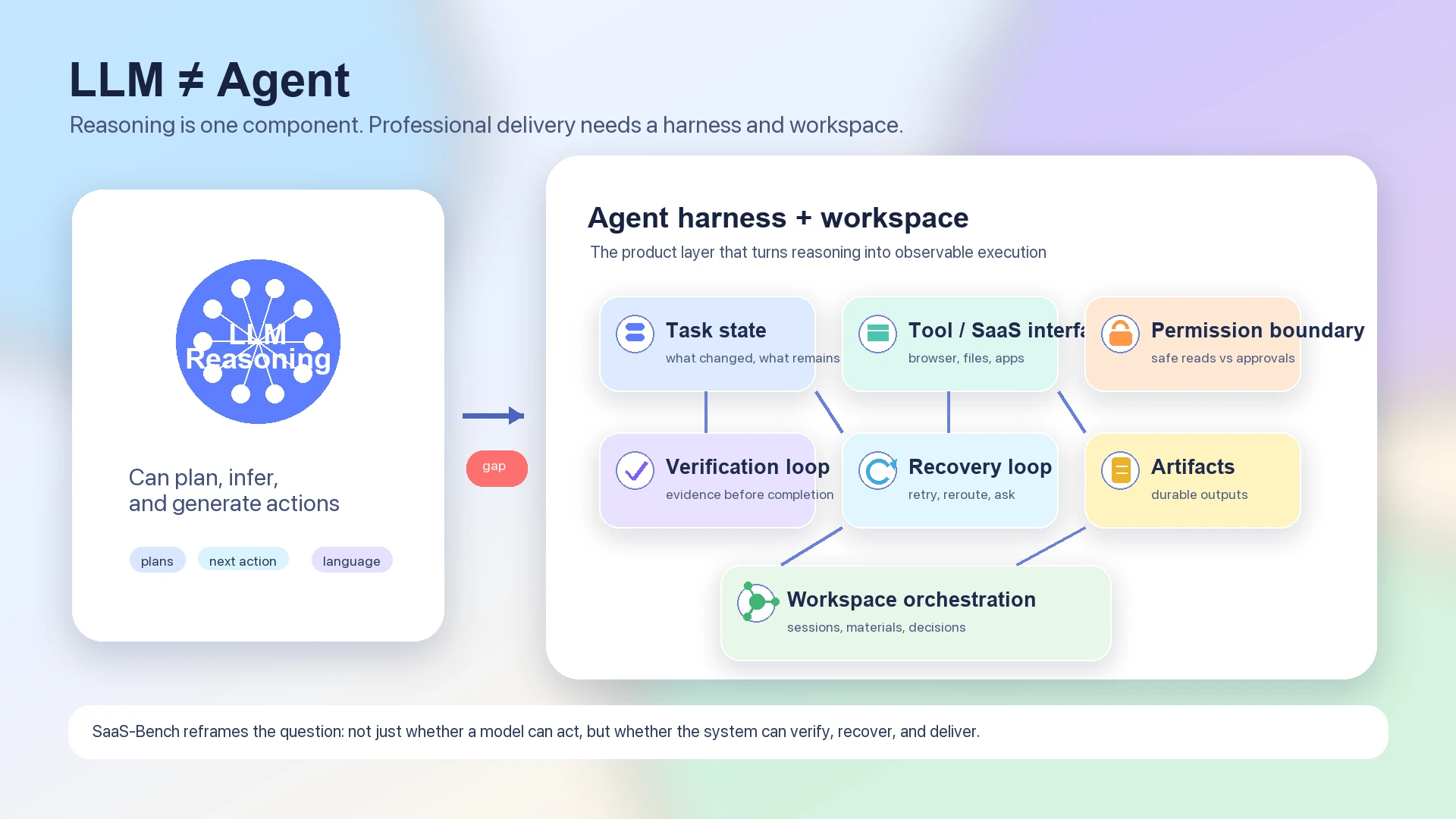
لهذا يناسب benchmark نقاش agent architecture أكثر من ترتيب النماذج البسيط. يستطيع LLM خالص أن يخطط ويستنتج ويولد next actions. لكن agent العامل يجب أن يحافظ أيضا على state عبر خطوات كثيرة، ويتحقق مما إذا كان العالم قد تغير كما هو متوقع، ويعرف متى يطلب permission، ويعيد المحاولة بأمان، ويترك artifacts قابلة للفحص.
النموذج هو محرك التفكير. أما harness فهو نظام التنفيذ.
LLM لا يساوي Agent
تضغط عبارة "AI agent" غالبا عدة طبقات في كلمة واحدة. يجعل SaaS-Bench هذا الضغط أصعب دفاعا عنه.
يمكن لنموذج لغة أن ينتج خطة مثل "افتح CRM، حدّث سجل العميل، أرفق المستند الموقّع، أخطر الفريق، وسوّ الفاتورة". لكن workflow المهني يتطلب أكثر من خطة. يتطلب من النظام أن يعرف أي browser state هو الحالي، وأي SaaS app هو المصدر الموثوق، وأي ملف هو artifact of record، وأي action قابل للعكس، وأي action يحتاج user approval، وأي checkpoint يثبت أن المهمة اكتملت.
 LLM مكون واحد داخل agent harness و workspace architecture أوسع
LLM مكون واحد داخل agent harness و workspace architecture أوسع
لذلك يحتاج agent stack المفيد إلى هذه الطبقات على الأقل:
| الطبقة | ما الذي تضيفه |
|---|---|
| LLM reasoning | يفسر الأهداف، يصوغ الخطط، يختار next actions، ويشرح trade-offs. |
| Task state | يتتبع ما تم إنجازه، وما لا يزال مفتوحا، وأي افتراضات لم تتحقق بعد. |
| Tool and SaaS interface | يربط browser actions و documents و files و SaaS systems و external tools في capabilities قابلة للاستخدام. |
| Permission boundary | يميز actions الآمنة read-only عن actions التي تحتاج approval أو supervision صريحة. |
| Verification loop | يتحقق مما إذا كانت كل state transition مهمة قد حدثت فعلا. |
| Recovery loop | يتعامل مع failures و retries و partial completion وتغير UI state والنتائج غير المتوقعة. |
| Artifact discipline | ينتج documents و records و tables و tickets و reports أو code changes دائمة، لا chat replies فقط. |
| Workspace orchestration | ينسق sessions و materials و decisions و follow-up tasks متعددة بمرور الوقت. |
عندما تكون هذه الطبقات ضعيفة، قد يفشل نموذج أقوى أيضا. قد يستنتج بصورة صحيحة في المجرد ثم يفقد أثر العالم الملموس. قد يكمل معظم الخطوات المرئية ومع ذلك يفوّت verification condition الوحيدة التي تعرف النجاح. قد يكون قادرا على long reasoning لكنه يفتقر إلى mechanism آمن للعمل طويل التشغيل.
يقيس SaaS-Bench هذه الطبقات المفقودة بشكل غير مباشر. يوضح checkpoint score أن النماذج تستطيع المساهمة. ويوضح resolved score أن هذه المساهمة ليست كافية.
الفشل ليس مجرد "ذكاء النموذج"
من المغري قراءة جداول benchmark كسباق نماذج. هذا صحيح جزئيا، لكنه غير مكتمل.
في المهام القصيرة، قد تهيمن جودة النموذج. إذا كان العمل إجابة واحدة، فغالبا ما يفوز أقوى reasoning model. أما في workflows SaaS الطويلة، فيتغير توزيع الفشل. يجب أن يعمل agent في عالم stateful و permissioned و asynchronous و inconsistent. قد لا يعرض المتصفح العنصر المتوقع. قد يحفظ document في المكان الخطأ. قد يتطلب SaaS form تحقق validation مخفيا. قد يحتاج notification إلى الإشارة إلى artifact الصحيح. وقد يتطلب workflow العودة إلى app سابق بعد أن تغير خطوة لاحقة output المطلوب.
هذه harness problems بقدر ما هي reasoning problems.
قد يختار نموذج أقوى actions أفضل، لكنه ما يزال يحتاج إلى بيئة تستطيع الإجابة عن أسئلة تشغيلية:
- ما source of truth الحالي؟
- ما الذي تغير بعد آخر action؟
- أي checkpoint لديه evidence، وأي checkpoint هو assumed فقط؟
- أي step آمن للretry؟
- أي operation يتطلب user approval؟
- أي artifact ينبغي تسليمه كالنتيجة النهائية؟
- أي failure ينبغي أن يطلق recovery بدلا من continued execution؟
هذا هو الفرق بين chatbot يستطيع وصف العمل و agent system يستطيع تسليم العمل.
إشارة موازية من SaaSBench آخر
هناك benchmark آخر باسم مشابه، ولا ينبغي الخلط بينه وبين SaaS-Bench. benchmark SaaSBench الموجه إلى coding هو benchmark مختلف يركز على مهام software engineering معقدة.3 يتضمن إعداده المعلن 30 complex tasks و 5,370 validation nodes و 8 languages و 6 databases و 13 frameworks، مع وقوع أكثر من 95% من failures قبل أن تصل agents إلى deep business logic.3
الbenchmarkان مختلفان، لكن الإشارة الموازية مفيدة. سواء كانت البيئة professional SaaS operations أو multi-service software engineering، تحدث failures كثيرة قبل أن يصل النظام إلى أعمق domain reasoning. تتعطل agents عند scaffolding: setup و state و dependencies و interfaces و validation و recovery.
هذا لا يجعل تقدم النماذج غير مهم. بل يغير ما يجب أن يقترن به تقدم النماذج.
طبقة المنتج تتحول إلى Agent Harness
تنتقل صناعة agents من سباق نماذج إلى سباق أنظمة تنفيذ.
ليس harness الجيد مجرد مجموعة tools. إنه طبقة منتج على مستوى workspace تجعل agent work قابلا للفحص والحوكمة. يجب أن يساعد المستخدم على فهم ما يفعله agent، وما فعله بالفعل، وما evidence الذي يدعم completion، وأين تكون human judgment مطلوبة.
بالنسبة إلى workflows على نمط SaaS-Bench، تحتاج harness layer إلى عدة خصائص.
State continuity. تتطلب workflows الطويلة أكثر من context stuffing. يحتاج النظام إلى معرفة الفرق بين user instruction و model hypothesis و observed UI state و saved artifact و verified decision.
Checkpoint-aware execution. إذا كانت المهمة تعتمد على سلسلة outcomes، فيجب أن يشجع workspace على verification صريحة. يجب أن يكون التقدم الجزئي مرئيا، لكنه لا يجب أن يختلط مع completion.
Permission and action boundaries. غالبا ما تتضمن workflows SaaS المهنية records أو invoices أو medical administration أو team documents أو external communication. يحتاج agent system الناضج إلى approval points مرئية و defaults آمنة، خاصة حول actions غير القابلة للعكس أو externally visible.
Recovery rather than collapse. عندما تتغير UI أو تفشل tool، يجب ألا يواصل النظام ببساطة تخيل التقدم. ينبغي أن يكتشف uncertainty، ويحفظ failure evidence، ويعيد retry بأمان، أو يطلب decision من المستخدم.
Artifact-first output. نادرا ما يكون الناتج النهائي للعمل المهني chat answer. إنه report أو ticket أو spreadsheet أو submitted form أو document revision أو media asset أو decision record. يجب أن يتعامل harness مع هذه العناصر كdurable objects.
Workspace orchestration. كثير من workflows أوسع من thread واحد ضخم. يمكن فصل research و execution و verification و final reporting إلى sessions أو workstreams، ثم توفيقها بواسطة workspace-level coordinator.
لهذا يتقارب "agent harness" و "AI workspace". يمنح harness النموذج hands و guardrails و memory و inspection. ويمنح workspace المستخدم مكانا للإشراف والتنظيم ومواصلة العمل.
أين يناسب MCPlato
لا ينبغي قراءة SaaS-Bench كادعاء بأن أي workspace واحد قد حل العمل SaaS المستقل. لم تدّع MCPlato علنا أنها تشغل SaaS-Bench أو أنها تقضي على failure modes في benchmark. الخلاصة المسؤولة أضيق وأكثر عملية: يؤكد benchmark سبب أهمية workspace architecture.
صمم MCPlato حول فكرة أن agent work الجاد يحتاج إلى أكثر من chat transcript واحد. على مستوى عال، يمنح المستخدمين طريقة لتنظيم agent execution عبر workspaces و sessions و connected materials و visible artifacts و supervised continuation.
تتطابق عدة مفاهيم في MCPlato بشكل طبيعي مع درس SaaS-Bench:
- Multi-session orchestration. غالبا ما ينقسم العمل المهني الطويل إلى research و execution و review و synthesis. تساعد sessions المنفصلة على حفظ الحدود مع السماح للمستخدم بتنسيق الهدف العام.
- Sprite / virtual partner. يمكن لworkspace-level partner أن يساعد على تتبع ما هو active، وما هو blocked، وما هو complete، وما لا يزال يحتاج review. القيمة هي orchestration، لا الاستعراض.
- Artifact discipline. يجب أن تتحول outputs إلى deliverables قابلة للفحص: documents و reports و plans و diagrams و code changes أو files أخرى يمكن مراجعتها خارج chat flow.
- Local-first connected materials. يعتمد العمل الحقيقي على local documents و project folders و notes و source materials. يمكن لworkspace يحافظ على هذه materials قريبة من task أن يقلل context loss.
- Scheduled and background tasks. يستفيد بعض agent work من continuation خارج chat turn متزامن واحد، خاصة عندما يتضمن research أو checking أو batch production.
- Permissioned and observable execution. يجب أن يستطيع المستخدمون رؤية actions التي تمت تجربتها، وأن يقرروا متى تتطلب step ما approval، خاصة عندما يلمس agent external systems أو durable artifacts.
- Decision trace. تحتاج workflows الطويلة إلى memory لما تم accepted أو rejected أو deferred ولماذا. من دون هذه trace، قد تلغي step لاحقة من agent عن طريق الخطأ rationale خطوة سابقة.
الصياغة المهمة هي "يساعد على التنظيم والإشراف". لا يجعل workspace harness كل agent مستقلا أو صحيحا أو آمنا افتراضيا. إنه يمنح المستخدم و agent execution surface أفضل: سطحا تكون فيه state و artifacts و permissions و recovery جزءا من product experience بدلا من أن تكون مخفية داخل transcript.
ما الذي يقترحه SaaS-Bench عن موجة Agents التالية
يشير benchmark إلى تعريف أكثر واقعية لagent progress.
لن يحكم على agent system المفيد التالي فقط بمدى طلاقته في reasoning النصي. سيحكم عليه بما إذا كان يستطيع الحفاظ على continuity عبر التطبيقات، وحفظ evidence، والتعافي من partial failures، وطلب permission في الوقت الصحيح، وإنتاج artifacts يمكن للمهني أن يثق بها.
هذا معيار أعلى من "النموذج يستطيع استدعاء tools". Tool use هو الواجهة فقط. سؤال المنتج هو ما إذا كان harness المحيط يستطيع جعل tool use موثوقا عبر workflows طويلة.
يمنح SaaS-Bench الصناعة مفردات أوضح لهذه الفجوة:
- checkpoint progress ليس مثل resolved completion؛
- browser control ليس مثل professional workflow delivery؛
- model reasoning ليس مثل agent execution؛
- chat transcript ليس مثل workspace؛
- autonomy بلا observability ليست product strategy.
الخلاصة ليست أن النماذج الأكبر غير مهمة. إنها مهمة. لكن مع تحسن النماذج، تصبح failures المتبقية أكثر architectural. تتحرك جبهة المنافسة نحو harnesses و workspaces و verification loops و permission models و artifact systems.
ما يزال سباق النماذج مستمرا. ويشير SaaS-Bench إلى أن السباق التالي هو execution-system race.
References
Footnotes
-
SaaS-Bench arXiv paper و SaaS-Bench HTML version، بما في ذلك title و authors و task composition و multi-application statistics و workflow-step statistics و scoring definitions و Table 2 benchmark scores المذكورة في هذا المقال. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
Official SaaS-Bench benchmark page and live leaderboard، بما في ذلك official live leaderboard scores و 3,971 weighted checkpoints المذكورة. ↩ ↩2 ↩3 ↩4
-
SaaSBench coding benchmark arXiv paper. هذا benchmark مختلف عن SaaS-Bench؛ ويستشهد به فقط كإشارة مقارنة خلفية. ↩ ↩2